
зђЬьЪеЕНвЛИівЕЮёЭЌбЇЕФашЧѓгЪМўЃЌвЛАугааЉИДдгЕФашЧѓвЕЮёЭЌбЇЛсЗЂгЪМўИцжЊЮвУЧЃЌашвЊЮвУЧЦРЙРжЎКѓдйзіНЛИЖЃЌЮвПДСЫгЪМўжЎКѓЃЌЗЂЯжетИіашЧѓКУЯёгаЕуБ№ХЄЃЌДѓЬхЕФвтЫМЪЧдкжаМфМўЕФЛЗОГжаДДНЈвЛеХБэЃЌБэНсЙЙШчЯТЃК
- CREATE TABLE `app_loading_info` (
- `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'зддіID',
- `pid` bigint(20) NOT NULL DEFAULT '0' COMMENT ,
- `appid` int(11) NOT NULL DEFAULT '0' COMMENT 'APPID',
- `username` varchar(64) NOT NULL DEFAULT '' COMMENT 'аеУћ',
- `card` varchar(20) NOT NULL DEFAULT '' ,
- `ai` varchar(40) NOT NULL DEFAULT '' ,
- `state` int(11) NOT NULL DEFAULT '0' ,
- `ctime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'ДДНЈЪБМф',
- `mtime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'ИќаТЪБМф',
- PRIMARY KEY (`id`),
- KEY `idx_pid` (`pid`),
- KEY `idx_state` (`state`)
- ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
АДееIDЗжЦЌЃЌЛљБОТпМШчЯТЃК
УПЬьЛсШЅЩИбЁЮЊЭъГЩДІРэЕФгУЛЇЪ§ОнЃЌжиаТДІРэЃЌДІРэЭъГЩКѓЛсШЅаоИФгУЛЇЕФвЛИіБъжОЮЛЃЌжївЊгаМИИіВНжшЃК
1)ИљОнstateзДЬЌЬсШЁstate=0ЕФЪ§Он(ЮДЭъГЩДІРэЪ§Он)
2)ГЬађжаАДееidЮЊЧјМфЗжХњЬсШЁ
3)ЬсШЁЭъГЩКѓаоИФstateЮЊstate=1,ИљОнpid,stateзщКЯ
ПДСЫетИіГѕВНЕФЩшМЦжЎКѓЃЌЮвзмЪЧИаОѕФФРяВЛЖдЃЌгкЪЧеввЕЮёЭЌбЇУцЖдУцЙЕЭЈЁЃ
ЪзЯШЖдгкетИіБэЕФЖЈвхЩЯЃЌвЕЮёЭЌбЇЫЕЪЧЙщЪєгкзДЬЌБэЃЌвВОЭвтЮЖзХБэжаЕФУПвЛИігУЛЇЖМгаЮЈвЛЕФзДЬЌжЕЖдгІЃЌетИіБэжаДцДЂЕФЪ§ОнСПЛсдНРДдНДѓЁЃ
ЦфДЮЃЌАДееstateзДЬЌзжЖЮШЅЬсШЁЮДЭъГЩДІРэЕФЪ§ОнЃЌетИіФПБъЛЗОГЪЧвЛЬзМЏШКЛЗОГЃЌМЏШКжаЪЧАДееidНјааЗжЦЌЃЌЕЋЪЧВщбЏЬѕМўАДееstateЪЧгаЧБдкЮЪЬтЕФЁЃ
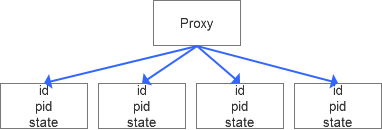
БШШчвЕЮёВуЖдгкзддіidЕФЪЙгУЃЌдкЗжЦЌЛЗОГжаПЩФмЪЧВЛЮЈвЛЕФЃЌШчЩЯЭМЫљЪОЃЌПЩФмid=1зюЖрЛсДцдкNЬѕЭЌбљЕФЪ§Он(NЮЊЗжЦЌЪ§)ЃЌЫљвдДгвЕЮёашЧѓЩЯЪЧВЛЬЋФмТњзуЕФЁЃ
СэЭтИљОнstate=0ШЅВщбЏЪ§ОнЃЌетИіВщбЏЕФИДдгЖШНЯИпЃЌвВОЭвтЮЖзХstate=0ашвЊБщРњЫљгаЕФЗжЦЌЃЌУПИіЗжЦЌжаЛсЭЈЙ§state=0ЕФЫїв§ЬѕМўЙ§ТЫЪ§ОнзюКѓЛузмЦ№РДЃЌДгЪЙгУЩЯРДЫЕЃЌетвВЪЧЗжПтЗжБэЕФвЛИіЧБдкгАЯьЃЌВЛЪЧКмНЈвщетжжЪЙгУЗНЪНЁЃ
ЛЙгазжЖЮidЕФЩшМЦЃЌАДеезДЬЌБэЕФЪЙгУЗНЪНЃЌвВЪЧВЛКЯРэЕФЃЌдквЛаЉЬиЪтЕФГЁОАжаЮвУЧЛсВЩгУid+ЦфЫћвЕЮёЪєадзжЖЮзщКЯжїМќЃЌ дкетРяетжжГЁОАЯдШЛВЛЪЧЁЃ
ШчЙћШЅЕєidзжЖЮВЩгУжїМќЕФФЃЪНЃЌКУЯёОЭЮЅБГСЫвЕЮёГѕждИљОнidНјааЧјМфЬсШЁЕФЗНЪНЃЌЯИЯИЦЗРДетИіашЧѓЪЧУЌЖмЕФЁЃ
ШчЙћАДеезюУуЧПЕФЗНЪНЃЌНЈвщЪЧжИЖЈЪБМфЗЖЮЇФкДІРэЃЌБШШч8ЕуЕН9ЕужЎМфДІРэЃЌетИіжЎЭтЕФЪБМфЗЖЮЇОЭВЛвЊзіРрЫЦаФЬјЛђепЗўЮёМьВтЕФДІРэСЫЃЌЖдгквЕЮёВрРДЫЕЃЌЛЙЪЧФмЙЛЛљБОНгЪмЕФЃЌЕЋЪЧЮоТлШчКЮетВЛЪЧвЛжжзюгХНтЃЌЖјЧвЖдгкЫїв§ЕФЪЙгУЪЕдкгауЃгкжаМфМўЗўЮёЪЙгУЕФГѕждЁЃ
ОЙ§НјвЛВНЕФЙЕЭЈЃЌЮвУЧдйДЮЭкОђашЧѓЃЌЖдгкРяУцЕФБэЪ§ОнЪЧШчКЮДІРэЕФЃЌвЕЮёЭЌбЇЫЕЦфЪЕБэжаЕФЪ§ОнШчЙћЪБМфГЄСЫжЎКѓЪЧашвЊПМТЧЪ§ОнЧхРэЕФЃЌЫљвдАДееетжжФЃЪНЃЌетИіашЧѓЕФОЭЛљБОЧхЮњСЫЃЌКЭГѕЪМашЧѓгаБШНЯДѓЕФВювьЁЃ
ЕНСЫетРяашЧѓЕФЗНЯђЦфЪЕОЭгаСЫДѓЕФзЊелЃЌетИіБэАДееФПЧАЕФашЧѓЦфЪЕЪЙгУШежОБэЕФФЃЪНвЊИќКУвЛаЉЃЌБШШчБэжаЕФЪ§ОнЪЧАДееШчЯТЕФСаБэЧщПіДцДЂЃЌвдШеЦкБэЮЊЮЌЖШНјааДцДЂЁЃ

ШчЙћашвЊАДееT+1ЕФФЃЪНШЅДІРэЮДЭъГЩЕФЪ§ОнЃЌећИіИДдгЖШжЛеыЖдФГвЛЬьЕФБэжДааЫїв§ЩЈУшЃЌВЛЛсЖдЦфЫћЕФБэВњЩњЙиСЊгАЯьЃЌЖјШчЙћАДееШеЦкЮЊЕЅБэДцДЂЃЌећИіЪТЧщЕФздгЩЖШОЭИќДѓСЫЃЌАДееstateЛђепЪЧpidЕФЮЌЖШНјааВщбЏЃЌаЇЙћЖМЪЧПЩвдНгЪмЕФЁЃ
ЫљвдзюКѓОЙ§ЬжТлКЭЦРЙРЃЌЦфЪЕУЛгаБивЊдкжаМфМўЛЗОГжаНјааИУРрвЕЮёЕФДІРэЃЌЯрБШЖјбдЃЌадМлБШвВВЛИпЁЃЖјЛљгкжаМфМўЕФЗўЮёГаНгЕФЪЧЦЋКЫаФЕФвЕЮёЃЌЖдгкадФмКЭИКдиЕФгАЯьНЯЮЊУєИаЃЌШчЙћЯЁРяК§ЭПОЭжДааСЫЃЌЦфЪЕКѓУцЛсДјРДвЛаЉЦфЫћЕФвўЛМЁЃ
ЭЈЙ§етбљвЛИіПДЦ№РДМђЕЅЕФашЧѓЕФЙЕЭЈКЭЭкОђЃЌзюКѓВњЩњСЫВЛЭЌЕФНтОіЗНАИЃЌЖдгквЕЮёВрРДЫЕЛЙЪЧБШНЯТњвтЕФЃЌжСЩйФмЙЛГЌГіЫћУЧЕФЛљБОашЧѓЦкЭћЪЕЯжЃЌЖјЧвКмЖрЯИНкЕФЙЄзївВВЛашвЊИќЖрЕФШЫЙЄВЮгыКЭКѓЦкЬжТлЃЌДѓДѓМѕЩйСЫЙЕЭЈЕФБпМЪГЩБОЁЃ
вдЩЯНіЪЧвЛИіашЧѓЕФЬжТлЙ§ГЬЃЌВЛДњБэЗНАИЪЧзюгХЕФЃЌНіЙЉВЮПМЁЃ
БОЮФзЊдиздЮЂаХЙЋжкКХЁИбюНЈШйЕФбЇЯАБЪМЧЁЙЃЌПЩвдЭЈЙ§вдЯТЖўЮЌТыЙизЂЁЃзЊдиБОЮФЧыСЊЯЕбюНЈШйЕФбЇЯАБЪМЧЙЋжкКХЁЃ

БОЮФзЊдиздЭјТчЃЌдЮФСДНгЃКhttps://mp.weixin.qq.com/s/l1KUZcIHVaKmyerdVIWoxw
 ЯрЙиЮФеТ
ЯрЙиЮФеТ

 ОЋВЪЕМЖС
ОЋВЪЕМЖС
 ШШУХзЪбЖ
ШШУХзЪбЖ