
自打构建数据源集市的技术栈以来,其实整个体系也在不断的完善,在数据流转的出口方向我们基本达成了一致,那就是在保证数据准确性和稳定性的基础上尽可能按照实时的标准去落地数据交付效率,所以数据源集市的目标不是简单交付数据了事,而是需要对中下游的服务提供强有力的支持,甚至提供数据实时流转的参考和依据。
目前一张表的数据如果要提供近实时的数据交付标准,一般有以下的几类策略:
1)基于自增ID的模式,根据数据库的自增ID可以快速的定位数据的增量位置,基本实现数据的增量同步,当然这种模式的局限性比较大,需要表中含有自增ID字段,对于数据库的吞吐量也会有潜在瓶颈,同时不适用于基于中间件的集群环境数据实时流转。
2)基于时间字段同步模式,时间字段的同步是表数据实现增量同步的经典方法,也是和业务紧密结合,但是带来的潜在风险是可能相关的时间字段有多个,同步定制化程度高,另外单一使用增量模式其实难以完全定位数据,还是需要另外一个维度的支持,比如自增ID等。
如果一张状态表要实现实时流转,实时交付,那么面临的问题其实是比较复杂的。
通常这类状态表数据量巨大,但很可能没有基于自增ID的字段(通常是基于业务的ID字段),而基于时间字段基本可行,但是难以快速定位唯一的记录内容,最紧要的一点是我们通过唯一性定位得到的是变化后的值,变化前的值已经被完全覆盖,所以对于变化量的定义是比较复杂的。
目前来看,碰到的一些瓶颈问题主要有:
中下游的数据服务提取数据时,尽管数据源是实时更新的,但是后续的数据服务是难以定位增量数据的。通过上述的多个维度都不合适,通常做数据检查的时候只能无奈使用select count(*) from xxx这种校验模式,而要解决这个问题最直接的方案就是程序段提供相应的流水日志,如果开发能力较强这个事情比较好落地,而如果业务风险高,这个事情要解决就比较麻烦了。
如下是一种折中的解决方案,在不需要程序修改代码的前提下,能够实时提取数据变化并实时更新同步数据状态,大体的设计思路是基于实时日志服务,在这里是Maxwell.
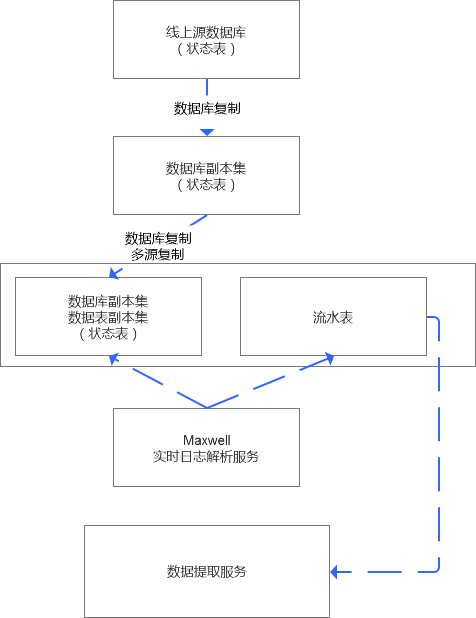
我来简单解释下,如果一张状态表的数据要实时交付,那么数据源集市中我们保证状态表的数据实时复制是没有问题的,技术上完全能够做到,无论是基于库级别还是过滤到表级别,都是可操作的。
而基于Maxwell的实时日志提取,我们可以从状态表中解析出表中数据实时变化的内容,我们可以间接实现一个账单表,对于中下游来说,就是间接把状态表转换为流水日志表,从而间接实现的实时流转和交付。
本文转载自微信公众号「杨建荣的学习笔记」,可以通过以下二维码关注。转载本文请联系杨建荣的学习笔记公众号。

本文转载自网络,原文链接:https://mp.weixin.qq.com/s/pAFWBi09BhRDpFv0JAieMA
 相关文章
相关文章

 精彩导读
精彩导读
 热门资讯
热门资讯