
ЁОБрепЕФЛАЁП2018Фъ1дТOpenAIЙйЗНВЉПЭГЦЃЌЫћУЧвбНЋKubernetesМЏШКРЉеЙЕН2500ИіНкЕуЁЃЪБИєШ§ФъЃЌдк2021Фъ1дТЃЌOpenAIЙйЗНВЉПЭдйЖШаћВМKubernetesМЏШКРЉеЙЕН7500ИіНкЕуЃЌФПЧАВЛНіПЩвдТњзуGPT-3ЁЂCLIP КЭDALL·EЕШДѓаЭФЃаЭЕФашЧѓЃЌЖјЧввВПЩвдЗўЮёгкПьЫйЕФаЁЙцФЃЕќДњбаОПЁЃЯТУцЮФеТРДздгкOpenAIЙйЗНВЉПЭЃЌУшЪіСЫзпЯђетИі7500НкЕуЙцФЃЙ§ГЬжагіЕНЕФЮЪЬтКЭНтОіАьЗЈЃЌвдМАЖдгкЮДРДзпЯђЕФГЉЯыЁЃ
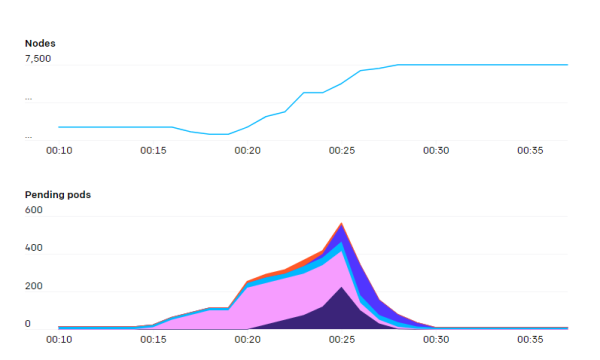
ЮвУЧЕФKubernetesМЏШКЙцФЃвбОЩЯЩ§ЕН7,500ИіНкЕуЃЌжївЊЮЊжюШчGPT-3ЁЂCLIPКЭDALL·EЕШДѓаЭбЕСЗФЃаЭЬсЙЉПЩРЉеЙЕФЛљДЁМмЙЙЃЌЖјЧвЛЙПЩгУгкаЁЙцФЃПьЫйЕќДњбаОПЃЌР§ШчЩёОгябдФЃаЭЕФБъЖШТЩЕШЁЃНЋЕЅИіKubernetesМЏШКРЉеЙЕНШчДЫЙцФЃКмФбЭъГЩЃЌЭЌЪБдкетИіЙ§ГЬжаашвЊИёЭтаЁаФЁЃЕЋКУДІЪЧНшжњетжжМђЕЅЕФЛљДЁМмЙЙЪЙЕУЮвУЧЕФЛњЦїбЇЯАбаОПЭХЖгЮоашИќИФЦфДњТыОЭПЩвдПьЫйРЉШнЁЃ
здЩЯвЛЦЊгаЙиРЉеЙЕН2,500ИіНкЕуЕФЮФеТЗЂБэвдРДЃЌЮвУЧвЛжБдкВЛЖЯРЉеЙЛљДЁМмЙЙвдТњзубаОПШЫдБЕФашЧѓЃЌдкДЫЙ§ГЬжаЮвУЧЛЙбЇЕНСЫКмЖрОбщЁЃетЦЊЮФеТЖдДЫзїСЫзмНсЃЌвдБуKubernetesЩчЧјЙВЭЌЪмвцЃЌзюКѓНщЩмЮвУЧШдШЛвЊУцЖдЕФЮЪЬтвдМАНтОіАьЗЈЬНЬжЁЃ
ЙЄзїИКди
дкЮвУЧЩюШыЬжТлжЎЧАЃЌНщЩмвЛЯТЮвУЧЕФЙЄзїИКдиЪЧКмживЊЕФЁЃЮвУЧдЫааKubernetesШэгВМўКЭФњдкЙЋЫОЕФЧщПіПЩФмВЛЬЋвЛбљЁЃЮвУЧЕФЮЪЬтКЭЯргІЕФНтОіЗНАИПЩФмЪЧЃЌвВПЩФмВЛЪЧЃЌвВЧыФњЪгЧщПіЖјгІгУ!
ДѓаЭЛњЦїбЇЯАзївЕПчдНаэЖрНкЕуЃЌВЂЧвжЛгаЕБПЩвдЗУЮЪУПИіНкЕуЩЯЕФЫљгагВМўзЪдДЪБЃЌВХФмзюДѓЛЏдЫаааЇТЪЁЃШчДЫвЛРДЃЌGPUОЭПЩвдЭЈЙ§ NVLinkжБНгНјааНЛВцЭЈаХЃЌЛђепGPUвВПЩвдЭЈЙ§GPUDirectжБНггыNICЭЈаХЁЃвђДЫЃЌЖдгкЮвУЧЕФаэЖрЙЄзїИКдиЃЌвЛИіНкЕуЩЯжЛЗХжУвЛИіPodЁЃШЮКЮNUMAЁЂCPUЛђPCIEзЪдДељгУЖМВЛЪЧЕїЖШЕФвђЫиЃЌвђДЫзАЯфЕїЖШЛђЫщЦЌЛЏВЛЪЧвЛИіГЃМћЕФЮЪЬтЁЃЮвУЧЯжгаЕФМЏШКгЕгаЭъећЕФЖдЗжДјПэЃЌвђДЫвВЮоашПМТЧШЮКЮЛњМмЛђЭјТчЭиЦЫЁЃЫљгаетаЉЖМБэУїЃЌЮвУЧЕФKubernetesгЕгааэЖрНкЕуЃЌЕЋЪЧЕїЖШЕФбЙСІЯрЖдНЯЕЭЁЃ
ВЛЙ§ЃЌkube-schedulerЩЯОГЃЛсГіЯжЗхжЕбЙСІЁЃвЛИіаТЕФJobПЩФмАќКЌЪ§АйИівЛДЮадДДНЈЕФPodЃЌЕЋОпгаНЯЕЭЕФЪЙгУТЪЁЃ
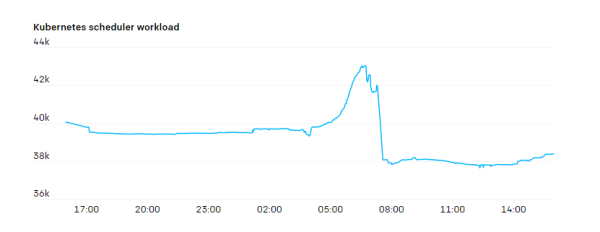
ЮвУЧзюДѓЕФJobЩЯдЫаазХ MPI авщ(ЯћЯЂДЋЕнНгПкавщ)ЃЌИУJobФкЕФЫљгаPodЖММгШыСЫЭЌвЛИіMPIЭЈаХЦїЁЃШчЙћФГИіPodхДЛњЃЌдђећИіJobЖМНЋднЭЃЃЌашвЊжиаТЦєЖЏЁЃЮвУЧЛсЖЈЦкБЃДцМьВщЕуЃЌJobжиЦєЪБЛсДгЩЯвЛИіМьВщЕуЛжИДЁЃвђДЫЃЌПЩвдШЯЮЊPodЪЧАызДЬЌЛЏЕФЃЌжежЙЕФPodПЩвдБЛЬцЛЛЕєЃЌЖјЧвJobЛЙПЩвдМЬајЃЌЕЋЪЧетжжзіЗЈЛсИЩШХе§ГЃЕФJobЃЌгІОЁСПМѕЩйЁЃ
гЩгкHTTPSЭЈЕРСїСПКмЩйЃЌвВВЛашвЊНјааA/BВтЪдЁЂРЖ/ТЬЛђН№ЫПШИВПЪ№ЃЌЮвУЧУЛгаЭъШЋвРРЕKubernetesНјааИКдиОљКтЁЃPodжЎМфЭЈЙ§SSH(ЖјВЛЪЧЗўЮёЖЫЕу)ЃЌРћгУIPЕижЗжБНгЭЈЙ§MPIЯрЛЅЭЈаХЁЃЮвУЧЕФЗўЮё“ЗЂЯж”ЙІФмКмгаЯоЃЌвЛАужЛашвЊдкJobЦєЖЏЕФЪБКђжДаавЛДЮВщевШЅевЕНMPIжаЕФPodЁЃ
ЮвУЧЕФДѓЖрЪ§JobЖМЪЙгУСЫФГжжаЮЪНЕФBlobДцДЂЁЃЭЈГЃЃЌЫќУЧЛсжБНгДгBlobДцДЂЃЌвдСїЕФаЮЪНЖСШЁЪ§ОнМАЛђМьВщЕуЕФФГаЉЗжЦЌЃЌЛђНЋЦфЛКДцЕНСйЪБЕФБОЕиДХХЬЁЃдкашвЊPOSIXгявхЕФЪБКђЃЌЮвУЧвВЪЙгУСЫвЛаЉГжОУОэЃЌЕЋЪЧBlobДцДЂИќШнвзРЉеЙЃЌЖјЧвВЛашвЊЛКТ§ЕФЗжРы/ИНМгВйзїЁЃ
зюКѓвЊЬсабЃЌЮвУЧЕФЙЄзїДѓЖрЪЧЛљгкбаОПаджЪЕФЃЌетвтЮЖзХИКдиБОЩэдкВЛЖЯБфЛЏЁЃОЁЙмГЌЫуЭХЖгХЌСІЬсЙЉСЫЩњВњМЖБ№ЕФМЦЫуЛљДЁМмЙЙЃЌЕЋМЏШКЩЯдЫааЕФгІгУГЬађЕФЩњУќжмЦкКмЖЬЃЌЖјЧвПЊЗЂШЫдБЕФЕќДњЗЧГЃПьЁЃаТЕФЪЙгУФЃЪНЫцЪБПЩФмГіЯжЃЌвђДЫЮвУЧКмФбдЄСЯЗЂеЙЧїЪЦЃЌВЂзіГіЪЪЕБЕФелжаЁЃЮвУЧашвЊвЛИіПЩГжајЗЂеЙЕФЯЕЭГЃЌвдБудкЪТЧщЗЂЩњБфЛЏЪБбИЫйзіГіЯьгІЁЃ
ЭјТч
гЩгкМЏШКФкЕФNodeЪ§КЭPodЪ§ВЛЖЯдіГЄЃЌЮвУЧЗЂЯжFlannelФбвдРЉеЙЕНЫљашЕФЭЬЭТСПЁЃгкЪЧЃЌЮвУЧзЊЖјЪЙгУдЩњPodЭјТчММЪѕРДЙмРэAzure VMSSesЕФIPХфжУКЭЯрЙиЕФCNIВхМўЁЃетбљЮвУЧЕФPodОЭФмЙЛЛёЕУЫожїМЖБ№ЕФЭјТчЭЬЭТЁЃ
ЮвУЧзюДѓЕФМЏШКЩЯДѓдМга20ЭђИіIPЕижЗе§дкЪЙгУжаЃЌдкВтЪдЛљгкТЗгЩЕФPodЭјТчЪБЃЌЮвУЧЗЂЯжПЩвдгааЇРћгУЕФТЗгЩЪ§СПЪмЕНСЫбЯжиЯожЦЁЃвђДЫЮвУЧИФгУЛљгкБ№УћЕФIPбАжЗЁЃ
БмУтЗтзАдіМгСЫЖдЕзВуSDNЛђТЗгЩв§ЧцЕФвЊЧѓЃЌЕЋЫќЪЙЮвУЧЕФЭјТчЩшжУБЃГжМђЕЅЁЃЮоашШЮКЮЖюЭтЕФЪЪХфЦїОЭПЩвдЬэМгЫэЕРЁЃЮвУЧВЛашвЊЕЃаФЪ§ОнАќЗжЦЌЃЌвђЮЊЭјТчЕФФГаЉВПЗжMTUНЯЕЭЁЃЭјТчВпТдКЭСїСПМрПивВКмМђЕЅ;Ъ§ОнАќЕФдДКЭФПЕФЕиВЛДцдкЦчвхЁЃ
ЮвУЧдкЫожїЩЯЪЙгУiptablesРДИњзйУПИіУќУћПеМфКЭPodЩЯЭјТчзЪдДЕФЪЙгУЧщПіЁЃетбљбаОПШЫдБОЭПЩвдПЩЪгЛЏЭјТчЕФЪЙгУЧщПіЁЃОпЬхРДЫЕЃЌвђЮЊаэЖрЪЕбщЕФЛЅСЊЭјКЭPodМфЭЈаХЖМгаЖРЬиЕФФЃЪНЃЌЫљвдФмЙЛЕїВщКЮДІПЩФмГіЯжЦПОБЪЧЗЧГЃБивЊЕФЁЃ
iptablesЕФmangleЙцдђПЩвдИјШЮКЮЗћКЯЬиЖЈЙцдђЕФЪ§ОнАќзіБъМЧЁЃЮвУЧВЩгУСЫвдЯТЙцдђРДМьВтСїСПЪєгкФкВПЛЙЪЧЗЂЯђЭтЭјЁЃFORWARDЙцдђИКд№PodМфЕФСїСПЃЌЖјINPUTКЭOUTPUTИКд№РДздЫожїЕФСїСПЃК
- iptables -t mangle -A INPUT ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in"
- iptables -t mangle -A FORWARD ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in"
- iptables -t mangle -A OUTPUT ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out"
- iptables -t mangle -A FORWARD ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter
зіКУБъМЧКѓЃЌiptablesОЭЛсЭГМЦЗћКЯИУЙцдђЕФЪ§ОнАќЕФзжНкЪ§ЁЃЪЙгУiptablesУќСюОЭПЩвдПДЕНетаЉЭГМЦНсЙћЃК
- % iptables -t mangle -L -v
- Chain FORWARD (policy ACCEPT 50M packets, 334G bytes)
- pkts bytes target prot opt in out source destination
- ....
- 1253K 555M all -- any any anywhere !10.0.0.0/8 /* iptables-exporter openai traffic=internet-out */
- 1161K 7937M all -- any any !10.0.0.0/8 anywhere
ЮвУЧЪЙгУСЫвЛИіУћЮЊ iptables-exporter ЕФПЊдД Prometheus ЕМГіГЬађЃЌНЋетаЉИњзйаХЯЂЕМГіЕНМрПиЯЕЭГжаЁЃетбљОЭПЩвджБНгИњзйЗћКЯИїжжЬѕМўЕФЪ§ОнАќСЫЁЃ
ЮвУЧЕФЭјТчФЃаЭЕФЖРЬижЎДІдкгкЃЌNodeЁЂPodКЭЗўЮёЭјТчЕФCIDRЗЖЮЇЪЧЭъШЋБЉТЖИјбаОПепЕФЁЃЭјТчВЩгУСЫТжЗјФЃаЭЃЌЪЙгУдЩњНкЕуКЭPodЕФCIDRЗЖЮЇНјааТЗгЩЁЃбаОПепСЌНгЕНжабыЪрХІЃЌДгФЧРяПЩвдЗУЮЪЕНШЮКЮМЏШКЁЃЕЋЪЧСНИіМЏШКжЎМфВЛФмЛЅЯрЭЈаХЁЃетбљПЩвдБЃжЄУПИіМЏШКЖМЪЧИєРыЕФЃЌВЛЛсГіЯжПчМЏШКвРРЕ(ЗёдђЛсЦЦЛЕЙЪеЯИєРыддђ)ЁЃ
ЮвУЧЪЙгУвЛИі“NAT”ЫожїЖдРДздМЏШКЭтВПЕФСїСПНјааCIDRЗЖЮЇзЊвыЁЃетжжНсЙЙПЩвдШУбаОПШЫдБздгЩЕибЁдёЪЙгУКЮжжЭјТчХфжУвдМАдѕбљЪЙгУЃЌвдТњзуЪЕбщЕФашвЊЁЃ
API Servers
ЖдгкНЁПЕЙЄзїЕФМЏШКРДНВЃЌ API ServersКЭetcdЪЧKubernetesЕФЙиМќзщМўЃЌЫљвдЮвУЧЬиБ№ЙизЂетаЉзщМўЁЃЮвУЧВЩгУСЫkube-prometheusЬсЙЉЕФGrafanaвЧБэАхЃЌвдМАздМКЩшМЦЕФвЧБэАхЁЃЮвУЧЗЂЯжЃЌеыЖдAPI ServersЩЯЗЂЩњЕФHTTP 429(Too Many Requests)КЭ5xx(Server Error)ЗЂЫЭИпМЖБ№БЈОЏЗЧГЃгааЇЁЃ
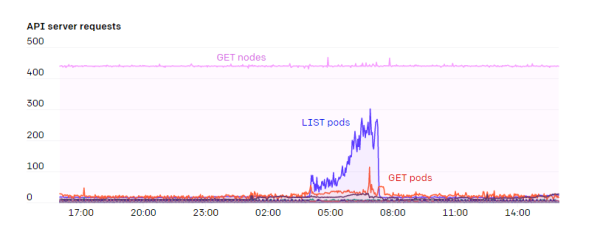
ЫфШЛаэЖрШЫдкKubernetesФкВПдЫааAPI ServersЃЌЕЋЮвУЧбЁдёСЫдкМЏШКЭтВПдЫааЁЃetcdКЭAPI ServersЖМдЫаадкЖРСЂЕФНкЕуЩЯЁЃзюДѓЕФМЏШКдЫааСЫ5ИіAPI ServersКЭ5ИіetcdНкЕуЃЌВЂвдЗжЩЂИКдиМѕаЁхДЛњдьГЩЕФгАЯьЁЃздДгНЋKubernetes EventsЗжРыЕНЕЅЖРЕФetcdМЏШКЩЯвдКѓЃЌОЭдйвВУЛгаГіЯжЙ§вђetcdЮЪЬтЕМжТЕФЙЪеЯЁЃAPI ServersЪЧЮозДЬЌЕФЃЌвђДЫжЛашвЊдЫаавЛИіздЮваоИДЕФЪЕР§зщЛђscalesetОЭПЩвдЁЃЮвУЧУЛгаГЂЪдЙ§еыЖдetcdМЏШКЙЙНЈздЮваоИДздЖЏЛЏЃЌвђЮЊЫќМЋЩйГіЙЪеЯЁЃ
API ServersеМгУЕФФкДцЯрЕБЖрЃЌЖјЧвФкДцеМгУЛсЫцзХМЏШКжаЕФНкЕуЪ§СПдіМгЖјГЪЯпаддіГЄЁЃЖдгкЮвУЧгЕга7500НкЕуЕФМЏШКЃЌУПИіAPI ServersЩЯЕФЖбПеМфеМгУзюЖрЮЊ70GBЃЌЛЙКУетвРШЛдкгВМўФмЙЛГаЪмЕФЗЖЮЇФкЁЃ

API ServersЩЯБШНЯДѓЕФбЙСІжЎвЛОЭЪЧЖЫЕуЩЯЕФWATCHЁЃгаМИИіЗўЮёЕФЗўЮёЖдЯѓЪЧМЏШКжаЕФЫљгаГЩдБЃЌШчkubeletЁЂnode-exporterЕШЁЃУПЕБМЏШКжаЬэМгЛђЩОГ§НкЕуЪБЃЌОЭЛсДЅЗЂWATCHЁЃЖјЧвгЩгкУПИіНкЕуздЩэЖМЛсЭЈЙ§kube-proxyМрЪгkubeletЗўЮёЃЌетаЉЗўЮёЕФЯьгІЪ§СПКЭЫљашДјПэОЭЛсГЪN^2діГЄЃЌДѓдМУПУыдіМг1 GBЁЃKubernetes 1.17жаЗЂВМЕФEndpointSlicesМЋДѓЕиЛКНтСЫетИібЙСІЃЌЫќНЋИКдиНЕЕЭСЫ1000БЖЁЃ
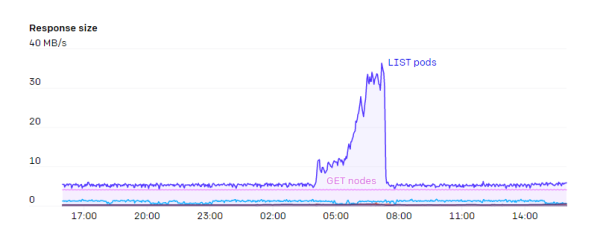
вЛАуЖјбдЃЌЮвУЧЛсзЂвтШЮКЮAPI ServersЧыЧѓЪ§СПЫцзХМЏШКДѓаЁЖјБфЛЏЕФЧщПіЁЃЮвУЧЛсОЁСПБмУтШУШЮКЮDaemonSetгыAPI ServersНЛСїЁЃШчЙћашвЊШУУПИіНкЕуМрПиБфЛЏЃЌФЧУДв§ШыжаМфЛКДцЗўЮё(ШчDatadogCluster Agent)ЛђаэЪЧБмУтМЏШКЗЖЮЇЦПОБЕФКУАьЗЈЁЃ
ЫцзХМЏШКЕФдіГЄЃЌЮвУЧЕФздЖЏЩьЫѕдНРДдНЩйСЫЁЃЕЋХМЖћвВЛсГіЯжДѓЗљздЖЏЩьЫѕЕФЧщПіЁЃаТЕФНкЕуМгШыМЏШКЛсВњЩњаэЖрЧыЧѓЃЌЖјвЛДЮаддіМгМИАйИіНкЕуЛсГЌЙ§API ServersФмЙЛГаЪмЕФШнСПЁЃЦНЛЌЧыЧѓЫйЖШЃЌЩѕжСНіНідіМгМИУыжгЃЌОЭПЩвдгааЇЕиБмУтетИіЮЪЬтЁЃ
ЪЙгУPrometheusКЭGrafanaВтСПЪБађСаЖШСП
ЮвУЧЪЙгУPrometheusЪеМЏЪБађСаЖШСПЃЌРћгУGrafanaЛцжЦГЩЭМБэЁЂЯдЪОвЧБэАхВЂЩњГЩОЏИцЁЃЪзЯШЮвУЧВПЪ№СЫkube-prometheusРДЪеМЏИїжжЖШСПКЭПЩЪгЛЏЕФвЧБэАхЁЃЫцзХЪБМфЕФЭЦвЦЃЌЮвУЧвбОЬэМгСЫаэЖрЮвУЧздМКЕФвЧБэАхЁЂжИБъКЭОЏБЈЁЃ
ЫцзХНкЕудНРДдНЖрЃЌЮвУЧж№НЅФбвдРэНтPrometheusЪеМЏЕНЕФЖШСПЁЃОЁЙмkube-prometheusЙЋПЊСЫаэЖрЗЧГЃгагУЕФЪ§ОнЃЌЕЋгааЉЪ§ОнЮвУЧВЂВЛашвЊЃЌЖјгааЉЪ§ОнЙ§гкЯИжТЃЌКмФбЪеМЏЁЂДцДЂКЭгааЇЕиВщбЏЁЃвђДЫЮвУЧЪЙгУPrometheus Йцдђ“ЗХЦњ”СЫвЛаЉЖШСПЁЃ
ГЄЦквдРДЃЌгавЛИіЮЪЬтвЛжБРЇШХЮвУЧЃКPrometheusЯћКФЕФФкДцдНРДдНЖрЃЌзюжегЩгкФкДцКФОЁЖјБРРЃЁЃМДЪЙИјPrometheusЬсЙЉДѓСПЕФФкДцвВЮоМУгкЪТЁЃИќдуИтЕФЪЧЃЌУПЕБГіЯжБРРЃЃЌЫќОЭашвЊЛЈЗбКУМИИіаЁЪБжиаТжДаадЄаДЪНШежО(write-ahead log)ЮФМўЃЌжЎКѓВХФме§ГЃЪЙгУЁЃ
зюКѓЮвУЧбаОПСЫPrometheusЕФдДДњТыЃЌЗЂЯжФкДцКФОЁЪЧгЩгкGrafanaКЭPrometheusжЎМфЕФНЛЛЅЕМжТЕФЃЌGrafanaЛсЪЙгУPrometheusЩЯЕФ/api/v1/seriesетИіAPIЃЌНјаа{le!=""}ЕФВщбЏ(КЌвхЪЧ“ЛёШЁЫљгажБЗНЭМЕФЖШСП”)ЁЃЖј/api/v1/seriesЕФЪЕЯждкдЫааЪБМфКЭПеМфЩЯЖМУЛгаШЮКЮЯожЦЃЌШчЙћВщбЏНсЙћЙ§ЖрЃЌОЭЛсЯћКФдНРДдНЖрЕФФкДцКЭЪБМфЁЃМДЪЙЧыЧѓепЗХЦњЧыЧѓВЂЙиБеСЌНгЃЌВщбЏвВЛсМЬајжДааЁЃЖдгкЮвУЧЕФЧщПіЖјбдЃЌЮоТлЖрЩйФкДцЖМВЛЙЛЃЌPrometheusзюжезмЛсБРРЃЁЃгкЪЧЃЌЮвУЧИјPrometheusДђСЫВЙЖЁЃЌНЋетИіAPIАќЙќдквЛИіContextжавдЪЕЯжГЌЪБЃЌжегкаоИДСЫИУЮЪЬтЁЃ
ЫфШЛPrometheusЕФБРРЃДЮЪ§ДѓДѓМѕЩйСЫЃЌЕЋЮвУЧвРШЛашвЊОГЃжиЦєЃЌвђДЫдЄаДЪНШежО(МђГЦWAL)ЕФжиаТжДаавРШЛЪЧвЛИіЮЪЬтЁЃжиаТжДааЫљга WAL ЭЈГЃашвЊЛЈЗбКУМИИіаЁЪБЃЌжЎКѓPrometheusВХФмЦєЖЏЃЌВЂПЊЪМЪеМЏЖШСПКЭВщбЏЧыЧѓЁЃдкRobust PerceptionЕФАяжњЯТЃЌЮвУЧЗЂЯжЩшжУGOMAXPROCS=24ПЩвдМЋДѓЕиИФЩЦетИіЮЪЬтЁЃвђЮЊPrometheusЛсдкжДааWALЦкМфГЂЪдЪЙгУЫљгаCPUКЫаФЃЌЖдгкКЫаФЪ§СПМЋЖрЕФЗўЮёЦїЖјбдЃЌКЫаФжЎМфЕФОКељЛсЕМжТадФмДѓЗљЖШЯТНЕЁЃ
ЮвУЧе§дкЬНЫїаТЕФбЁЯюЃЌвддіМгЮвУЧЕФМрВтФмСІЃЌШчЯТУцЕФ“ЮДНтОіЕФЮЪЬт”вЛНкЫљЪіЁЃ
НЁПЕМьВщ
УцЖдШчДЫХгДѓЕФМЏШКЃЌЮвУЧБиаывРРЕздЖЏЛЏРДМьВтВЂвЦГ§ШЮКЮгаЮЪЬтЕФНкЕуЁЃТ§Т§ЕиЃЌЮвУЧНЈСЂЦ№СЫвЛЯЕСаНЁПЕМьВщЯЕЭГЁЃ
БЛЖЏНЁПЕМьВщ
вЛаЉНЁПЕМьВщЪЧБЛЖЏЕФЃЌгРдЖдкНкЕуЩЯдЫааЁЃетаЉНЁПЕМьВщЛсМрЪгЛљБОЕФЯЕЭГзЪдДЃЌШчЭјТчВЛЭЈГЉЁЂДХХЬЪЇАмЁЂДХХЬаДТњЛђGPUДэЮѓЕШЁЃGPUЛсГЪЯжЖржжДэЮѓЃЌЕЋзюГЃМћЕФОЭЪЧ“Uncorrectable ECC error”(ЮоЗЈаоИДЕФECCДэЮѓ)ЁЃNvidiaЕФData Center GPU Manager (DCGM)ЙЄОпПЩвдАяжњВщбЏИУДэЮѓЃЌвдМАаэЖрЦфЫћЕФ“Xid”ДэЮѓЁЃИњзйДэЮѓЕФЗНЗЈжЎвЛОЭЪЧЪЙгУdcgm-exporterЙЄОпНЋЖШСПЕМГіЕНPrometheusМрЪгЯЕЭГжаЁЃетбљОЭПЩвдДДНЈDCGM_FI_DEV_XID_ERRORSЖШСПЃЌЦфФкШнЮЊзюНќЗЂЩњЙ§ЕФДэЮѓДњТыЁЃДЫЭтЃЌNVMLDevice Query APIЛЙПЩвдЬсЙЉгаЙиGPUЕФНЁПЕЧщПіКЭВйзїЕФИќЯъЯИаХЯЂЁЃ
МьВтЕНДэЮѓжЎКѓЃЌЭЈГЃжиЦєОЭФмаоИДGPUЛђЯЕЭГЃЌОЁЙмгааЉЧщПіЯТашвЊИќЛЛЯдПЈЁЃ
СэвЛжжНЁПЕМьВщЛсИњзйРДздЩЯгЮдЦЗўЮёЬсЙЉЩЬЕФЮЌЛЄЪТМўЁЃУПИіжїСїдЦЗўЮёЬсЙЉЩЬЖМЛсЬсЙЉвЛжжЗНЗЈЃЌЛёжЊЕБЧАЪЙгУЕФVMЪЧЗёМДНЋЮЌЛЄЃЌДгЖјЕМжТЗўЮёжаЖЯЁЃVMПЩФмашвЊжиЦєЃЌвђЮЊашвЊИјМрЪгГЬађДђВЙЖЁЃЌЛђепИјЮяРэЗўЮёЦїИќЛЛгВМўЁЃ
етаЉБЛЖЏНЁПЕМьВщдкЫљгаНкЕуЕФКѓЬЈВЛЖЯдЫааЁЃШчЙћдЫаазДПіМьВщПЊЪМЪЇАмЃЌНЋздЖЏИєРыИУНкЕуЃЌетбљОЭВЛЛсдкИУНкЕуЩЯЕїЖШаТЕФPodЁЃЖдгкИќбЯжиЕФНЁПЕМьВщЪЇАмЃЌЮвУЧЛЙНЋГЂЪджежЙPodЃЌЧыЧѓЫљгаЕБЧАдЫааЕФPodСЂМДЭЫГіЁЃЫќШдШЛШЁОігкPodБОЩэЃЌЭЈЙ§PodжаЖЯдЄЫуНјааХфжУЃЌвдОіЖЈЫќЪЧЗёЯЃЭћдЪаэетжжжежЙЗЂЩњЁЃзюжеЃЌдкЫљгаPodжежЙЛђ7ЬьЙ§ШЅ(ЮвУЧSLAЕФвЛВПЗж)жЎКѓЃЌЮвУЧНЋЧПжЦжежЙVMЁЃ
жїЖЏGPUВтЪд
ВЛавЕФЪЧЃЌВЂЗЧЫљгаЕФGPUЮЪЬтЖМФмДгDCGMжаПДЕНДэЮѓТыЁЃЮвУЧздМКЙЙНЈСЫGPUВтЪдПтЃЌФмЙЛВЖЛёЖюЭтЕФДэЮѓЃЌШЗБЃгВМўКЭЧ§ЖЏГЬађАДеедЄЦкдЫааЁЃетаЉВтЪдЮоЗЈдкКѓЬЈдЫааЃЌвђЮЊдЫааВтЪдашвЊЖРеМGPUМИУыжгЛђМИЗжжгЁЃ
ЪзЯШЃЌЮвУЧЛсдкНкЕуЦєЖЏЪБдЫааВтЪдЃЌГЦЮЊ“дЄдЫаа”ЁЃЫљгаМгШыМЏШКЕФНкЕуЖМЛсМгЩЯ“preflight” ЮлШОВЂДђБъЧЉЁЃИУЮлШОПЩвдЗРжЙЦеЭЈPodБЛЕїЖШЕННкЕуЩЯЁЃШЛКѓХфжУвЛИіDaemonSetЃЌдкЫљгаДјгаИУБъЧЉЕФPodЩЯдЫаадЄдЫааВтЪдЁЃВтЪдГЩЙІКѓЃЌВтЪдГЬађЛсвЦГ§ЮлШОЃЌНкЕуОЭПЩвде§ГЃЪЙгУСЫЁЃ
ЮвУЧЛЙЛсдкНкЕуЕФЩњУќжмЦкФкЖЈЦкжДааВтЪдЁЃВтЪдЭЈЙ§CronJobдЫааЃЌвђДЫПЩвддкМЏШКжаЕФШЮКЮПЩгУНкЕуЩЯжДааЁЃЫфШЛетбљЮоЗЈПижЦВтЪддкФФИіНкЕуЩЯдЫааЃЌЕЋЮвУЧЗЂЯжЃЌжЛвЊЪБМфзуЙЛГЄЃЌЫќОЭФмЬсЙЉзуЙЛЕФВтЪдИВИЧЃЌЭЌЪБВЛЛсЖдЗўЮёдьГЩЬЋЖрИЩШХЁЃ
ХфЖюКЭзЪдДРћгУ
ЕБЮвУЧРЉДѓМЏШКЪБЃЌбаОПШЫдБПЊЪМЗЂЯжЫћУЧКмФбЛёЕУЗжХфИјЫќУЧЕФЫљгаФмСІЁЃДЋЭГЕФJobЕїЖШЯЕЭГгаКмЖрВЛЭЌЕФЬиадЃЌПЩвддкОКељЭХЖгжЎМфЙЋЦНЕидЫааЙЄзїЃЌЖјKubernetesУЛгаетаЉЬиадЁЃЫцзХЪБМфЕФЭЦвЦЃЌЮвУЧДгетаЉJobЕїЖШЯЕЭГжаЛёЕУСЫСщИаЃЌИјKubernetesЬэМгСЫМИИідЩњЙІФмЁЃ
Team taints
ЮвУЧдкУПИіМЏШКЖМгавЛИіЗўЮё“team-resource-manager”ЃЌЫќОпгаЖржжЙІФмЁЃЫќЕФЪ§ОндДЪЧвЛИіConfigMapЃЌЫќЮЊдкИјЖЈМЏШКжагаФмСІЕФЫљгабаОПЭХЖгжИЖЈдЊзщ(НкЕубЁдёЦїЁЂвЊгІгУЕФЭХЖгБъЧЉЁЂЗжХфЪ§СП)ЁЃЫќгыМЏШКжаЕФЕБЧАНкЕуБЃГжвЛжТЃЌДгЖјЩшжУЪЪЕБЪ§СПЕФНкЕуЁЃ
- openai.com/team=teamname:NoSchedule.
“team-resource-manager”ЛЙОпгавЛИіadmission webhookЗўЮёЃЌР§ШчЃЌЕБЬсНЛУПИізївЕЪБЃЌЛсИљОнЬсНЛепЕФЭХЖгГЩдБЩъЧыЯргІЕФШнШЬЖШЁЃЪЙгУtaintsдЪаэЮвУЧСщЛюЕидМЪјKubernetes PodЕїЖШГЬађЃЌР§ШчдЪаэЖдНЯЕЭгХЯШМЖЕФPodга“any”ШнШЬЖШЃЌетдЪаэЭХЖгдкВЛашвЊжиСПМЖаЕїЕФЧщПіЯТНшгУБЫДЫЕФФмСІЁЃ
CPU & GPU balloons
Г§СЫЪЙгУcluster-autoscalerРДЖЏЬЌЩьЫѕМЏШКжЎЭтЃЌЮвУЧЛЙЛсЩОç€жиаТЬэМгМЏШКФкЕФВЛНЁПЕНкЕуЁЃЪЕЯжЗНЗЈЪЧНЋМЏШКЕФзюаЁГпДчЩшжУЮЊСуЃЌзюДѓГпДчЩшжУЮЊПЩгУЕФШнСПЁЃЕЋЪЧЃЌШчЙћcluster-autoscalerПДЕНПеЯаНкЕуЃЌОЭЛсГЂЪдНЋМЏШКЪеЫѕжСБивЊЯоЖШДѓаЁЁЃДгаэЖрНЧЖШРДПД(VMЕФЦєЖЏбгГйЁЂдЄЗжХфЕФГЩБОЁЂЖдAPIЗўЮёЦїЕФгАЯь)РДПДЃЌетжжПеЯазДЬЌЕФЩьЫѕВЂВЛРэЯыЁЃ
ЫљвдЃЌЮвУЧЭЌЪБЮЊНіжЇГжCPUЕФЫожїКЭжЇГжGPUЕФЫожїв§ШыСЫЦјЧђВПЪ№ЁЃИУВПЪ№АќКЌвЛИіReplicaSetЃЌЦфжаЩшжУСЫЕЭгХЯШМЖPodЕФзюДѓЪ§СПЁЃетаЉPodЛсеМгУвЛИіНкЕуФкЕФзЪдДЃЌЫљвдздЖЏЫѕЗХЦїОЭВЛЛсШЯЮЊИУНкЕуЯажУЁЃЕЋЪЧгЩгкетаЉPodгХЯШМЖКмЕЭЃЌвђДЫЕїЖШЦїПЩвдЫцЪБНЋЦфЧ§ж№ЃЌИјеце§ЕФзївЕЬкГіПеМфЁЃ(ЮвУЧбЁдёСЫЪЙгУВПЪ№ЖјВЛЪЧDaemonSetЃЌБмУтDaemonSetдкНкЕуЩЯБЛШЯЮЊЪЧЯажУИКдиЁЃ)
ашвЊзЂвтЕФвЛЕуЪЧЃЌЮвУЧЪЙгУСЫPodЗДЧзКЭадРДБЃжЄPodзюжеЛсОљдШЕиЗжВМЕННкЕуЩЯЁЃKubernetesдчЦкАцБОЕФЕїЖШЦїдкДІРэPodЗДЧзКЭадЪБЕФадФмЮЊO(N^2)ЃЌВЛЙ§етвЛЕудк1.8АцБОКѓОЭаое§СЫЁЃ
гаЮЪЬтЕФЕїЖШ
ЮвУЧЕФЪЕбщОГЃЩцМАЕНвЛИіЛђЖрИіStatefulSetЃЌУПИіИКд№бЕСЗзївЕЕФвЛВПЗжЁЃжСгкгХЛЏЦїЃЌбаОПШЫдБвЊЧѓЫљгаЕФStatefulSetЖМБЛЕїЖШЃЌбЕСЗзївЕВХФмЭъГЩ(вђЮЊЮвУЧОГЃЪЙгУMPIРДаЕїгХЛЏЦїЕФИїИіГЩдБЃЌЖјMPIЖдгкзщФкГЩдБЪ§СПЕФБфЛЏЗЧГЃУєИа)ЁЃ
ЕЋЪЧЃЌKubernetesФЌШЯВЂВЛвЛЖЈЛсгХЯШТњзуФГИіStatefulSetЕФЫљгаЧыЧѓЁЃР§ШчЃЌШчЙћСНИіЪЕбщЖМвЊЧѓ100%ЕФМЏШКШнСПЃЌФЧУДKubernetesВЛвЛЖЈЛсЕїЖШФГИіЪЕбщЕФЫљгаPodЃЌЖјЪЧПЩФмЛсЮЊУПИіЪЕбщЕїЖШвЛАыЕФPodЃЌЕМжТЫРЫјзДЬЌЃЌУПИіЪЕбщЖМЮоЗЈЭъГЩЁЃ
ЮвУЧГЂЪдСЫМИжжЗНАИЃЌЕЋЖМгіЕНСЫвЛаЉМЋЖЫЧщПіЃЌЛсгые§ГЃPodЕФЕїЖШВњЩњГхЭЛЁЃKubernetes 1.18ЮЊКЫаФЕїЖШЦїв§ШыСЫвЛИіВхМўМмЙЙЃЌвђДЫЬэМгЙІФмБфЕУЗЧГЃШнвзСЫЁЃЮвУЧзюНќИеИеЗЂВМСЫCoscheduling pluginЃЌвдНтОіетИіЮЪЬтЁЃ
ЮДНтОіЕФЮЪЬт
ЫцзХЮвУЧЕФKubernetesМЏШКВЛЖЯРЉДѓЃЌЛЙгааэЖрЮЪЬтгаД§НтОіЁЃвЛаЉЮЪЬтАќРЈЃК
ЖШСП
дкФПЧАЕФЙцФЃЯТЃЌPrometheusздДјЕФTSDBДцДЂв§ЧцгааэЖрЮЪЬтЃЌР§ШчЫйЖШКмТ§ЁЂжиЦєЪБашвЊКмГЄЪБМфжиаТжДааWAL(дЄаДШыШежО)ЕШЁЃВщбЏвВКмШнвзЕМжТ“ВщбЏПЩФмЛсМгдиЙ§ЖрЪ§Он”ЕФДэЮѓЁЃЮвУЧе§дкЧЈвЦЕНгыPrometheusМцШнЕФСэвЛИіДцДЂКЭВщбЏв§ЧцЩЯЁЃ
PodЭјТчСїСП
ЫцзХМЏШКЕФРЉДѓЃЌУПИіPodЖМЛсеМгУвЛЖЈЕФЛЅСЊЭјДјПэЁЃвђДЫЃЌУПИіШЫЕФЛЅСЊЭјДјПэМгЦ№РДОЭЮоЗЈКіТдВЛМЦСЫЃЌЮвУЧЕФбаОПШЫдБгаПЩФмЮовтМфИјЛЅСЊЭјЕФЦфЫћВПЗжДјРДВЛПЩКіТдЕФзЪдДбЙСІЃЌР§ШчЯТдиЪ§ЁЃ
змНс
ЮвУЧЗЂЯжKubernetesЖдгкЮвУЧЕФбаОПашЧѓРДЫЕЪЧвЛИіЗЧГЃСщЛюЕФЦНЬЈЁЃЫќгаФмСІРЉДѓЙцФЃЃЌвдТњзузюПСПЬЕФЙЄзїИКдиЁЃВЛЙ§ЃЌKubernetesЛЙгаКмЖрашвЊИФНјЕФЕиЗНЃЌOpenAIЕФГЌМЖМЦЫуЭХЖгНЋМЬајЬНЫїKubernetesШчКЮРЉеЙЁЃ
БОЮФзЊдиздЭјТчЃЌдЮФСДНгЃКhttp://dockone.io/article/1721164
АцШЈЩљУїЃКБОЮФзЊдиздЭјТчЃЌзёб CC 4.0 BY-SA АцШЈавщЃЌзЊдиЧыИНЩЯдЮФГіДІСДНгКЭБОЩљУїЁЃБОеОзЊдиГігкДЋВЅИќЖргХауММЪѕжЊЪЖжЎФПЕФЃЌШчгаЧжШЈЧыСЊЯЕQQ/ЮЂаХЃК153890879ЩОГ§
 ЯрЙиЮФеТ
ЯрЙиЮФеТ-

Kubernetes NodeЙцФЃЭЛЦЦ7500
-
Н№ЩНдЦЗЂВМШЋаТЙщЕЕДцДЂВњЦЗ ЙЙНЈдЦЩЯ
-
жаЙњдЦМЦЫуЪаГЁЙцФЃНЋДя1000вкУРдЊЃЁ
-

.comгђУћУїФъПЊЪМЕїМлЃЁеЧЗљНЋИпДя22.5

 ОЋВЪЕМЖС
ОЋВЪЕМЖС
 ШШУХзЪбЖ
ШШУХзЪбЖ