
本文转载自微信公众号「 SH的全栈笔记」,作者 SH 。转载本文请联系SH的全栈笔记公众号。
如果你是一个有经验的后端或者服务器开发,那么一定听说过Redis,其全称叫Remote Dictionary Server。是由C语言编写的基于Key-Value的存储系统。说直白点就是一个内存数据库,既然是内存数据库就会遇到如果服务器意外宕机造成的数据不一致的问题。
这跟很多游戏服务器也是一样的,感兴趣的可以参考我之前的文章游戏服务器和Web服务器的区别。其数据首先会流向内存,基于快速的内存读写来实现高性能,然后定期将内存的数据中的数据落地。Redis其实也是这么个流程,基于快速的内存读写操作,单机的Redis甚至能够扛住10万的QPS。
Redis除了高性能之外,还拥有丰富的数据结构,支持大多数的业务场景。这也是其为什么如此受欢迎的原因之一,下面我们就来看一看Redis有哪些基础数据类型,以及他们底层都是怎么实现的。
1. 数据类型
其基础数据类型有String、List、Hash、Set、Sorted Set,这些都是常用的基础数据类型,可以看到非常丰富,几乎能够满足大部分的需求了。其实还有一些高级数据结构,我们在这章里暂时先不提,只聊基础的数据结构。
2. String
String可以说是最基础的数据结构了, 用法上可以直接和Java中的String挂钩,你可以把String类型用于存储某个标志位,某个计数器,甚至狠一点,序列化之后的JSON字符串都行,其单个key限制为512M。其常见的命令为get、set、incr、decr 、mget。
2.1 使用
- get 获取某个key,如果key不存在会返回空指针
- set 给key赋值,将key设置为指定的值,如果该key之前已经有值了,那么将被新的值给覆盖
- incr 给当前的key的值+1,如果key不存在则会先给key调用set赋值为0,再调用incr。当然如果该key的类型不能做加法运算,例如字符串,就会抛出错误
- decr 给当前key的值-1,其余的同上
- mget 同get,只是一次性返回多条数据,不存在的key将会返回空指针
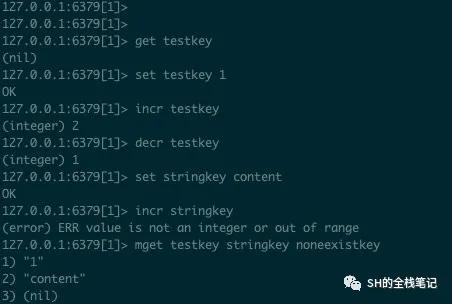
string相关命令
可能大多数的人只是到用一用的地步,这也无可厚非,但是如果是作为一个对技术有追求的开发,或者说你有想近大厂的想法,一定要有刨根问底的精神。只有当你真正知道一个东西的底层原理时,你遇到问题时才能提供给你更多的思路去解决问题。接下来我们就来聊一下Redis中String底层是如何实现的。
2.2 原理
2.2.1 结构
我们知道Redis是用C语言写的,但是Redis却没有直接使用,而是自己实现了一个叫SDS(Simple Dynamic String)的结构来实现字符串,结构如下。
- struct sdshdr {
- // 记录buf中已使用的字节数量
- int len;
- // 记录buf中未使用的字节数量
- int free;
- // 字节数组,用于保存字符串
- char buf[];
- }
2.2.2 优点
为什么Redis要自己实现SDS而不是直接用C的字符串呢?主要是因为以下几点。
- 减少获取字符串长度开销 C语言中获取字符串的长度需要遍历整个字符串,直到遇到结束标志位\0,时间复杂度为O(n),而SDS直接维护了长度的变量,取长度的时间复杂度为O(1)
- 避免缓冲区溢出 C语言中如果往一个字节数组中塞入超过其容量的字节,那么就会造成缓冲区溢出,而SDS通过维护free变量解决了这个问题。向buf数组中写入数据时,会先判断剩余的空间是否足够塞入新数据,如果不够,SDS就会重新分配缓冲区,加大之前的缓冲区。且加大的长度等于新增的数据的长度
- 空间预分配&空间惰性释放 C语言中,每次修改字符串都会重新分配内存空间,如果对字符串修改了n次,那么必然会出现n次内存重新分配。而SDS由于冗余了一部分空间,优化了这个问题,将必然重新分配n次变为最多分配n次,而数据从buf中移除的时候,空闲出来的内存也不会马上被回收,防止新写入数据而造成内存重新分配
- 保证二进制安全 C语言中,字符串遇到\0会被截断,而SDS不会因为数据中出现了\0而截断字符串,换句话说,不会因为一些特殊的字符影响实际的运算结果
可以结合下面的图来理解SDS。
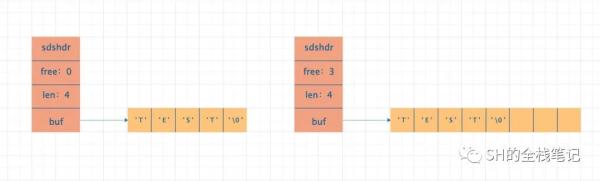
图片来源于网络,侵删
总结一下就是上面列表的四个小标题,为了减少获取字符串长度开销、避免缓冲区溢出、空间预分配&空间惰性释放和保证二进制安全。
3. List
List也是一个使用频率很高的数据结构,其涉及到的命令太多了,就不像String那样一个一个演示了,感兴趣的大家可以去搜一搜。命令有lpush、lpushx、rpush、rpushx、lpop、rpop、lindex、linsert、lrange、llen、lrem、lset、ltrim、rpoplpush、brpoplpush、blpop、brpop,其都是对数组中的元素的操作。
3.1 使用
List的用途我认为主要集中在以下两个方面。
当作普通列表存储数据(类似于Java的ArrayList)
用做异步队列
普通列表这个自然不必多说,其中存放的必然业务中需要的数据,下面来着重聊一下异步队列。
啥玩意,List还能当成队列来玩?
List除了能被用做队列,还能当作栈来使用。在上面介绍了很多操作List命令,当我们用rpush/lpop组合命令的时候,实际上就是在使用一个队列,而当我们用rpush/rpop命令组合的时候,就是在使用一个栈。lpush/rpop和lpush/lpop是同理的。
假设我们用的是rpush来生产消息,当我们的程序需要消费消息的时候,就使用lpop从异步队列中消费消息。但是如果采用这种方式,当队列为空时,你可能需要不停的去询问队列中是否有数据,这样会造成机器的CPU资源的浪费。
所以你可以采取让当前线程Sleep一段时间,这样的确可以节省一部分CPU资源。但是你可能就需要去考虑Sleep的时间,间隔太短,CPU上下文切换可能也是一笔不小的开销,间隔太长,那么可能造成这条消息被延迟消费(不过都用异步队列了,应该可以忽略这个问题)。
除了Sleep,还有没有其他的方式?
有,答案是blpop。当我们使用blpop去消费时,如果当前队列是空的,那么此时线程会阻塞住,直到下面两种condition。
- 达到设置的timeout时间
- 队列中有消息可以被消费
比起Sleep一段时间,实时性会好一点;比起轮询,对CPU资源更加友好。
3.2 原理
在Redis3.2之前,Redis采用的是ZipList(压缩列表)或者LinkedList(链表)。当List中的元素同时满足每个元素的小于64字节和List元素个数小于512个时,存储的方式为ZipList。但凡有一个条件没满足就会转换为LinkedList。
而在3.2之后,其实现变成了QuickList(快速列表)。LinkedList由于是较为基础的东西,此处就不赘述了。
3.2.1 ZipList
ZipList采用连续的内存紧凑存储,不像链表那样需要有额外的空间来存储前驱节点和后续节点的指针。按照其存储的区域划分,大致可以分为三个部分,每个部分也有自己的划分,其详细的结构如下。
- header ziplist的头部信息
- zlbytes 标识ziplist所占用的内存字节数
- zltail 到ziplist尾节点的偏移量
- zllen ziplist中的存储的节点数量
- entries 存储实际节点的信息
- pre_entry_length 记录了前一个节点的长度,通过这个值可以快速的跳转到上一个节点
- encoding 顾名思义,存储量元素的编码格式
- length 所存储数据的长度
- content 保存节点的内容
- end 标识ziplist的末尾
如果采用链表的存储方式,链表中的元素由指针相连,这样的方式可能会造成一定的内存碎片。而指针也会占用额外的存储空间。而ZipList不会存在这些情况,ZipList占用的是一段连续的内存空间。
但是相应地,ZipList的修改操作效率较为低下,插入和删除的操作会设计到频繁的内存空间申请和释放(有点类似于ArrayList重新扩容),且查询效率同样会受影响,本质上ZipList查询元素就是遍历链表。
3.2.2 QuickList
在3.2版本之后,list的实现就换成了QuickList。QuickList将list分成了多个节点,每一个节点采用ZipList存储数据。
4. Hash
其用法就跟Java中的HashMap中一样,都是往map中去丢键值对。
4.1 使用
基础的命令如下:
- hset 在hash中设置键值对
- hget 获hash中的某个key值
- hdel 删除hash中某个键
- hlen 统计hash中元素的个数
- hmget 批量的获取hash中的键的值
- hmset 批量的设置hash中的键和值
- hexists 判断hash中某个key是否存在
- hkeys 返回hash中的所有键(不包含值)
- hvals 返回hash中的所有值(不包含键)
- hgetall 获取所有的键值对,包含了键和值
其实大多数情况下的使用跟HashMap是差不多的,没有什么较为特殊的地方。
4.2 原理
hash的底层实现也是有两种,ZipList和HashTable。但具体采用哪一种与Redis的版本无关,而与当前hash中所存的元素有关。首先当我们创建一个hash的时候,采用的ZipList进行存储。随着hash中的元素增多,达到了Redis设定的阈值,就会转换为HashTable。
其设定的阈值如下:
- 存储的某个键或者值长度大于默认值(64)
- ZipList中存储的元素数量大于默认值(512)
ZipList上面我们专门简单分析了一下,理解这个设定应该也比较容易。当ZipList中的元素过多的时候,其查询的效率就会变得低下。而HashTable的底层设计其实和Java中的HashMap差不多,都是通过拉链法解决哈希冲突。具体的可以参考从基础的使用来深挖HashMap这篇文章。
5. Set
Set的概念可以与Java中的Set划等号,用于存储一个不包含重复元素的集合。
5.1 使用
其主要的命令如下,key代表redis中的Set,member代表集合中的元素。
- sadd sadd key member [...] 将一个或者多个元素加入到集合中,如果有已经存在的元素会忽略掉。
- srem srem key member [...]将一个或者多个元素从集合中移除,不存在的元素会被忽略掉
- smembers smembers key返回集合中的所有成员
- sismember dismember key member判断member在key中是否存在,如果存在则返回1,如果不存在则返回0
- scard scard key返回集合key中的元素的数量
- smove move source destination member将元素从source集合移动到destination集合。如果source中不包含member,则不会执行任何操作,当且仅当存在才会从集合中移出。如果destination已经存在元素则不会对destination做任何操作。该命令是原子操作。
- spop spop key随机删除并返回集合中的一个元素
- srandmember srandmember key与spop一样,只不过不会将元素删除,可以理解为从集合中随机出一个元素来。
- sinter 求一个或者多个集合的交集
- sinterstore sinterstore destination key [...]与sinter类似,但是会将得出的结果存到destination中。
- sunion 求一个或者多个集合的并集
- sunionstore sunionstore destination key [...]
- sdiff 求一个或者多个集合的差集
- sdiffstore sdiffstore destination key [...]与sdiff类似,但是会将得出的结果存到destination中。
5.2 原理
我们知道Java中的Set有多种实现。在Redis中也是,有IntSet和HashTable两种实现,首先初始化的时候使用的是IntSet,而满足如下的条件时,就会转换成HashTable。
- 当集合中保存的所有元素都是整数时
- 集合对象保存的元素数量不超过512
上面已经简单的介绍了HashTable了,所以这里只聊聊IntSet。
5.2.1 IntSet
intset底层是一个数组,既然数据结构是数组,那么存储数据就可以是有序的,这也使得intset的底层查询是通过二分查找来实现。其结构如下。
- struct intset {
- // 编码方式
- uint32_t encoding;
- // 集合包含元素的数量
- uint32_t length;
- // 存储元素的数组
- int8_t contents[];
- }
与ZipList类似,IntSet也是使用的一连串的内存空间,但是不同的是ZipList可以存储二进制的内容,而IntSet只能存储整数;且ZipList存储是无序的,IntSet则是有序的,这样一来,元素个数相同的前提下,IntSet的查询效率会更高。
6. Sorted
Set其与Set的功能大致类似,只不过在此基础上,可以给每一个元素赋予一个权重。你可以理解为Java的TreeSet。与List、Hash、Set一样,其底层的实现也有两种,分别是ZipList和SkipList(跳表)。
初始化Sorted Set的时候,会采用ZipList作为其实现,其实很好理解,这个时候元素的数量很少,采用ZipList进行紧凑的存储会更加的节省空间。当期达到如下的条件时,就会转换为SkipList:
- 其保存的元素数量的个数小于128个
- 其保存的所有元素长度小于64字节
6.1 使用
下面的命令中,key代表zset的名字;4代表score,也就是权重;而member就是zset中的key的名称。
- zadd zadd key 4 member用于增加元素
- zcard zcard key用于获取zset中的元素的数量
- zrem zrem key member [...]删除zset中一个或者多个key
- zincrby zincrby key 1 member给key的权重值加上score的值(也就是1)
- zscore zscore key member用于获取指定key的权重值
- zrange zrange key 0 -1获取zset中所有的元素,zrange key 0 -1 withscores获取所有元素和权重,withscores参数的作用是决定是否将权重值也一起返回。其返回的元素按照从小到大排序,如果元素具有相同的权重,则会按照字典序排序。
- zrevrange zrevrange key 0 -1 withscores,其与zrange类似,只不过zrevrange按照从大到小排序。
- zrangebyscore zrangebyscore key 1 5,返回key中权重在区间(1, 5]范围内元素。当然也可以使用withscores来将权重值一并返回。其元素按照从小到大排序。1代表min,5代表max,他们也可以分别是**-inf和inf**,当你不知道key中的score区间时,就可以使用这个。还有一个类似于SQL中的limit的可选参数,在此就不赘述。
除了能够对其中的元素添加权重之外,使用ZSet还可以实现延迟队列。
延迟队列用于存放延迟任务,那什么是延迟队列呢?
举个很简单的例子, 你在某个电商APP中下订单,但是没有付款,此时它会提醒你,「订单如果超过1个小时没有支付,将会自动关闭」;再比如在某个活动结束前1个小时给用户推送消息;再比如订单完成后多少天自动确认收货等等。
用人话解释一遍,那就是过会才要干的事情。
那ZSet怎么实现这个功能?
其实很简单,就是将任务的执行时间设置为ZSet中的元素权重,然后通过一个后台线程定时的从ZSet中查询出权重最小的元素,然后通过与当前时间戳判断,如果大于当前时间戳(也就是该执行了)就将其从ZSet中取出。
那,怎么取?
其实我看很多讲Redis实现延迟队列的博客都没有把这个怎么取讲清楚,到底该用什么命令,传什么参数。我们使用zrangebyscore命令来实现,还记得-inf和inf吗,其全称是infinity,分别表示无限小和无限大。
由于我们并不知道延迟队列当中的score(也就是任务执行时间)的范围,所以我们可以直接使用-inf和inf,完整命令如下。
- zrangescore key -inf inf limt 0 1 withscores
还是有点用,那ZSet底层是咋实现的呢?
上面已经讲过了ZipList,就不赘述,下面聊聊SkipList。
6.2 原理
6.2.1 SkipList
SkipList存在于zset(Sorted Set)的结构中,如下:
- struct zset {
- // 字典
- dict *dict;
- // 跳表
- zskiplist *zsl;
- }
而SkipList的结构如下:
- struct zskiplist {
- // 表头节点和表尾节点
- struct zskiplistNode *header, *tail;
- // 表中节点的数量
- unsigned long length;
- // 表中层数最大的节点的层数
- int level;
- }
不知道大家是否有想过,为什么Redis要使用SkipList来实现ZSet,而不用数组呢?
首先ZSet如果数组存储的话,由于ZSet中存储的元素是有序的,存入的时候需要将元素放入数组中对应的位置。这样就会对数组进行频繁的增删,而频繁的增删在数组中效率并不高,因为涉及到数组元素的移动,如果元素插入的位置是首位,那么后面的所有元素都要被移动。
所以为了应付频繁增删的场景,我们需要使用到链表。但是随着链表的元素增多,同样的会出现问题,虽然增删的效率提升了,但是查询的效率变低了,因为查询元素会从头到尾的遍历链表。所有如果有什么方法能够提升链表的查询效率就好了。
于是跳表就诞生了。基于单链表,从第一个节点开始,每隔一个节点,建立索引。其实也是单链表。只不是中间省略了节点。
例如存在个单链表 1 3 4 5 7 8 9 10 13 16 17 18
抽象之后的索引为 1 4 7 9 13 17
如果要查询16只需要在索引层遍历到13,然后根据13存储的下层节点(真实链表节点的地址),此时只需要再遍历两个节点就可以找到值为16的节点。
所以可以重新给跳表下一个定义,链表加多级索引的结构,就是跳表
在跳表中,查询任意数据的时间复杂度是O(logn)。时间复杂度跟二分查找是一样的。可以换句话说,用单链表实现了二分查找。但这也是一种用空间换时间的思路,并不是免费的。
End
关于Redis的基础数据结构和其底层的原理就简单的聊到这里,之后的几篇应该会聊聊Redis的高可用和其对应的解决方案,感兴趣的可以持续关注,公众号会比其他的平台都先更新。
本文转载自网络,原文链接:https://mp.weixin.qq.com/s/Pje0emTqS4S_IbtbVY9S5w
 相关文章
相关文章


 精彩导读
精彩导读
 热门资讯
热门资讯