如果没有恢复场景,备份就失去了业务价值,毕竟单纯靠业务价值一把尺子就衡量系统建设其实是不公平的,但是如果数据没有恢复成功,备份就失去了任何价值。
数据库这个圈子,其实比较垂直,能叫出名字的就是那么些人,所以数据恢复是一个很差的标签,而且删库跑路也是行不通的。
我们可以以退为进,把一些工作转变为主动。假设我有1000台数据库实例,其中从库和单实例节点有500个,那么如何保障这500个数据库实例的数据可以恢复,在可以恢复的前提下,如何提高恢复效率,然后整体上来看,如何综合提升备份效率,备份任务调度,如何通过增量来落实“一次全量,永远增量”的设计模式,这些措施都会有改进,但是对于数据恢复效率还是很难保证的。
比如下面的场景:
1)数据库参数配置不规范,/etc/my.cnf和/data/mysql_xxx/my.cnf的配置不匹配,导致实例启动失败
2)数据库版本差异化,比如主流支持是5.7,突然冒出来一个5.6的版本
3)binlog解析出错,导致后续恢复失败
4)备份集恢复出错,导致整体恢复失败
如此种种的案例数不胜数,稍有不慎,就难以恢复,而像配置类的问题,虽然可以解决,但是在紧急情况下,恢复流程失败,很难保证有良好的心态能够快速解决,所以对于恢复质量的检验是过去我们一直在犯的错误:我们一直在完善备份,但是对于恢复侧却少有关注,认为应该是可以的,恰恰是这个应该会把我们拖入被动局面。
所以我冒出来一个随机恢复的想法,还是假设有500个实例,那么这些实例如果我们一一恢复,每天的工作量是很庞大的,而且对系统的负载也很高,所以如果我们把风险和成本做一个综合,这个工作的效率和意义就会很明显。
目前的恢复主要有基于备份集恢复,基于时间点恢复,对象粒度的恢复和表结构恢复,我们通常所说的系统层恢复主要是基于备份集恢复和基于时间点恢复。
为此我设计和实现了如下的基本流程:
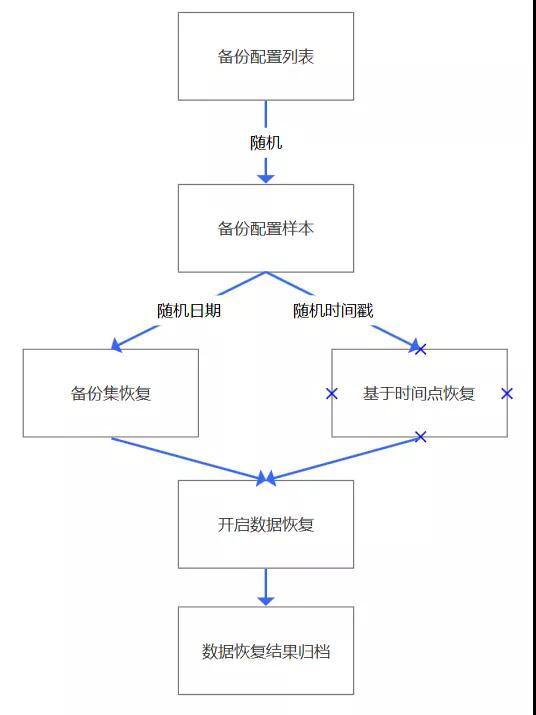
需要补充的是,随机时间是在备份集的时间周期内,而随机时间戳,则是按照近24小时内的一个随机时间点。
所以多次随机,能够让这个事情的判断会更加明确,恢复质量一目了然。
在这个基础上还需要一系列的事情:
1)随机需要保证在一定的时间范围内,所有实例都能够覆盖到
2)对恢复机进行线性扩展,比如提供一个恢复服务器组,可以在上面并行的跑一些恢复任务,提高恢复响应效率
3)对恢复结果进行日报可视化,恢复了哪些,效率如何,对一定时间周期内的恢复结果进行汇总和复盘
4)根据推断统计的思维,采取一定样本的数据,通过假设检验,建立相应的数据模型来进行检验和分析
本文转载自微信公众号「杨建荣的学习笔记」,可以通过以下二维码关注。转载本文请联系杨建荣的学习笔记公众号。

本文转载自网络,原文链接:https://mp.weixin.qq.com/s/Mp8PKXOv_VJN4sxWBSpBgw
 相关文章
相关文章

 精彩导读
精彩导读
 热门资讯
热门资讯