作为一个程序员,闲下来还是喜欢学习钻研一些新奇的技术,canal就成了很好的研究对象,一不小心就监控了公司MySQL的一举一动的
一、canal是个啥?
canal是阿里开发的一款基于数据库增量日志解析,提供增量数据订阅与消费的框架,整个框架纯JAVA开发,目前仅支持Mysql和MariaDB(和mysql类似)。
那什么是数据库增量日志?
MySQL的日志种类是比较多的,主要包含:错误日志、查询日志、慢查询日志、事务日志、二进制日志。而MySQL数据库所发生的数据变更(DML(data manipulation language)数据操纵语言,也就是我们熟悉的增删改),都会以二进制日志(binary log)形式存储。
二、canal原理
在介绍canal原理之前,我们先来回顾一下MySQL主从同步的原理,这或许会让你更好的理解canal的工作机制。
1、MySQL主从同步原理:
MySQL主从同步也叫读写分离,可以提升数据库的负载和容错能力,实现数据库的高可用
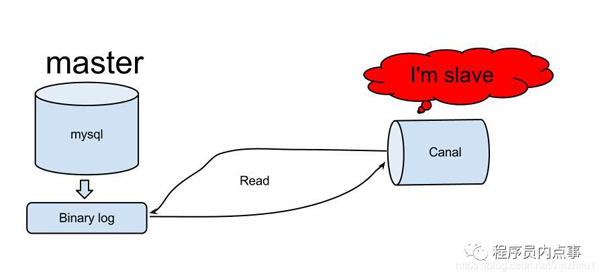
先来分析一张MySQL主从同步原理图:

以上图片源自网络,如有侵权联系删除
master节点操作过程:
当master节点数据发生更改后(delete、update、insert,还是创建函数、存储过程等操作),向binary log中写入记录日志,这些记录又叫做二进制日志事件(binary log events)。
- show binlog events
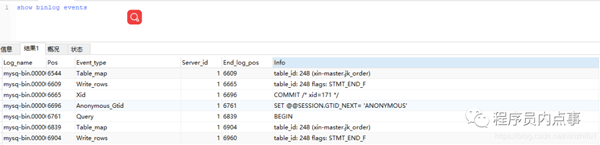
这些事件会按照顺序写入bin log中。当slave节点启动连接到master节点的时候,master节点会为slave节点开启binlog dump线程(负责传输binlog数据)。
一旦master节点的bin log发生变化时,bin logdump线程会通知slave节点有可以传输的binlog,并将相应的bin log内容发送给slave节点。
slave节点操作过程:
slave节点上会创建两个线程:一个I/O线程,一个SQL线程。I/O线程连接到master节点,master节点上的binlog dump 线程会将binlog的内容发送给该I\O线程。
该I/O线程接收到binlog内容后,再将内容写入到本地的relay log。而sql线程读取到I/O线程写入的ralay log,将relay log中的内容写入slave数据库。
2、canal原理
懂了上边MySQL的主从同步原理,canal的工作机制就很好理解了。
其实canal是模拟了MySQL数据库中,slave节点与master节点的交互协议,伪装自己为MySQL slave节点,向MySQL master节点发送dump协议,MySQL master节点收到dump请求,开始推送binary log给slave节点(也就是canal)。
以上图片源自网络,如有侵权联系删除
光说不练假把式,开干!
三、canal实现“监控”MySQL
在写代码前我们先对MySQL进行一下改造,安装MySQL就不再细说了,基本操作。
1、查看一下MySQL是否开启了binary log功能
- show binary logs
如果没有开启是图中的状态,一般用户是没有这个命令权限的,不过我有,啧啧啧!
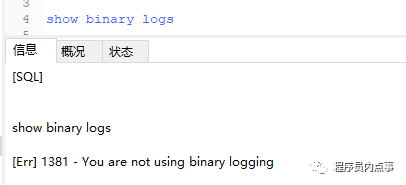
如果没有需要手动开启,并且在my.cnf文件中配置binlog-format 为Row模式
- log-bin=mysq-bin
- binlog-format=Row
log-bin是binlog文件存放位置
binlog-format 设置MySQL复制log-bin的方式
MySQL的三种复制方式:
基于SQL语句的复制(statement-based replication, SBR)
- 优点:将修改数据的sql保存在binlog,不需要记录每一条sql和数据变化,binlog体量会很小,IO开销少,性能好
- 缺点:会导致master-slave中的数据不一致
基于行的复制(row-based replication, RBR)
- 优点:不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了
- 缺点:binlog体积很大,尤其是在alter table属性时,会产生大量binlog数据
混合模式复制(mixed-based replication, MBR)
- 对应的,binlog的格式也有三种:STATEMENT,ROW,MIXED。
2、为canal 创建一个有权限操作MySQL的用户
- CREATE USER canal IDENTIFIED BY 'canal';
- GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
- -- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
- FLUSH PRIVILEGES;
3、安装canal
下载地址:https://github.com/alibaba/canal/releases
下载后选择版本例如:canal.deployer-xxx.tar.gz
4、配置canal
修改instance.properties文件,需要添加监听数据库和表的规则,canal可以全量监听数据库,也可以针对某个表进行监听,比较灵活。
- vim conf/example/instance.properties
- #################################################
- ## mysql serverId
- canal.instance.mysql.slaveId = 2020
- # position info 修改自己的数据库(canal要监听的数据库 地址 )
- canal.instance.master.address = 127.0.0.1:3306
- canalcanal.instance.master.journal.name =
- canal.instance.master.position =
- canal.instance.master.timestamp =
- #canal.instance.standby.address =
- #canal.instance.standby.journal.name =
- #canal.instance.standby.position =
- #canal.instance.standby.timestamp =
- # username/password 修改成自己 数据库信息的账号 (单独开一个 准备阶段创建的账号)
- canalcanal.instance.dbUsername = canal
- canalcanal.instance.dbPassword = canal
- canalcanal.instance.defaultDatabaseName =
- canal.instance.connectionCharset = UTF-8
- # table regex 表的监听规则
- # canal.instance.filter.regex = blogs\.blog_info
- canal.instance.filter.regex = .\*\\\\..\*
- # table black regex
- canal.instance.filter.black.regex =
启动canal
- sh bin/startup.sh
看一下server日志,确认一下canal是否正常启动
- vi logs/canal/canal.log
显示canal server is running now即为成功
- 2020-01-08 15:25:33.361 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## start the canal server.
- 2020-01-08 15:25:33.468 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[192.168.12.245:11111]
- 2020-01-08 15:25:34.061 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## the canal server is running now ......
5、编写Java客户端代码,实现canal监听
引入依赖包
- <dependency>
- <groupId>com.alibaba.otter</groupId>
- <artifactId>canal.client</artifactId>
- <version>1.1.0</version>
- </dependency>
这里只是简单实现
- public class MainApp {
- public static void main(String... args) throws Exception {
- /**
- * 创建与
- */
- CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),
- 11111), "example", "", "");
- int batchSize = 1000;
- int emptyCount = 0;
- try {
- connector.connect();
- /**
- * 监控数据库中所有表
- */
- connector.subscribe(".*\\..*");
- /**
- * 指定要监控的表,库名.表名
- */
- //connector.subscribe("xin-master.jk_order");
- connector.rollback();
- //120次心跳过后未检测到,跳出
- int totalEmptyCount = 120;
- while (emptyCount < totalEmptyCount) {
- Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
- long batchId = message.getId();
- int size = message.getEntries().size();
- if (batchId == -1 || size == 0) {
- emptyCount++;
- System.out.println("empty count : " + emptyCount);
- try {
- Thread.sleep(1000);
- } catch (InterruptedException e) {
- }
- } else {
- emptyCount = 0;
- // System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
- printEntry(message.getEntries());
- }
- /**
- * 提交确认
- */
- connector.ack(batchId);
- /**
- * 处理失败, 回滚数据
- */
- connector.rollback(batchId);
- }
- System.out.println("empty too many times, exit");
- } finally {
- connector.disconnect();
- /**
- * 手动开启事务回滚
- */
- //TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
- }
- }
- private static void printEntry(List<CanalEntry.Entry> entrys) {
- for (CanalEntry.Entry entry : entrys) {
- if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry
- .EntryType
- .TRANSACTIONEND) {
- continue;
- }
- CanalEntry.RowChange rowChage = null;
- try {
- rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
- } catch (Exception e) {
- throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
- e);
- }
- CanalEntry.EventType eventType = rowChage.getEventType();
- System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
- entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
- entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
- eventType));
- for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
- if (eventType == CanalEntry.EventType.DELETE) {
- printColumn(rowData.getBeforeColumnsList());
- } else if (eventType == CanalEntry.EventType.INSERT) {
- printColumn(rowData.getAfterColumnsList());
- } else {
- System.out.println("-------> before");
- printColumn(rowData.getBeforeColumnsList());
- System.out.println("-------> after");
- printColumn(rowData.getAfterColumnsList());
- }
- }
- }
- }
- private static void printColumn(List<CanalEntry.Column> columns) {
- for (CanalEntry.Column column : columns) {
- System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
- }
- }
- }
代码到这就编写完成了,我们启动服务看下是什么效果,由于并没有操作数据库,所以监听的结果都是空的。

接下来我们在数据库执行一条update语句试试
- update jk_orderset order_no = '1111' where id = 40
控制台检测到了数据库的修改,并生成binlog 日志文件mysql-bin.000009:3830

那么生成的binlog 文件该怎么用,如何解析成SQl语句呢?
- <!-- mysql binlog解析 -->
- <dependency>
- <groupId>com.github.shyiko</groupId>
- <artifactId>mysql-binlog-connector-java</artifactId>
- <version>0.13.0</version>
- </dependency>
将刚才的binlog文件下载本地测试一下
- public static void main(String[] args) throws IOException {
- String filePath = "C:\\ProgramData\\MySQL\\MySQL Server 5.7\\Data\\mysql-bin.000009:3830";
- File binlogFile = new File(filePath);
- EventDeserializer eventDeserializer = new EventDeserializer();
- eventDeserializer.setChecksumType(ChecksumType.CRC32);
- BinaryLogFileReader reader = new BinaryLogFileReader(binlogFile, eventDeserializer);
- try {
- for (Event event; (event = reader.readEvent()) != null; ) {
- System.out.println(event.toString());
- }
- } finally {
- reader.close();
- }
- }
查看一下执行结果,发现数据库最近的一次操作是加了一个idx_index索引
- Event{header=EventHeaderV4{timestamp=1551325542000, eventType=ANONYMOUS_GTID, serverId=1, headerLength=19, dataLength=46, nextPosition=8455, flags=0}, data=null}
- Event{header=EventHeaderV4{timestamp=1551325542000, eventType=QUERY, serverId=1, headerLength=19, dataLength=190, nextPosition=8664, flags=0}, data=QueryEventData{threadId=25, executionTime=0, errorCode=0, database='xin-master', sql='ALTER TABLE `jk_order`
- DROP INDEX `idx_index` ,
- ADD INDEX `idx_index` (`user_id`, `service_id`, `real_price`) USING BTREE'}}
- Event{header=EventHeaderV4{timestamp=1551438586000, eventType=STOP, serverId=1, headerLength=19, dataLength=4, nextPosition=8687, flags=0}, data=null}
至此我们就已经实现了监控MySQL
四、canal应用场景
canal应用场景大致有以下:
- 解决MySQL主从同步延迟的问题
- 实现数据库实时备份
- 多级索引 (卖家和买家各自分库索引)
- 实现业务cache刷新
- 价格变化等重要业务消息
重点分析一下canal是如何解决MySQL主从同步延迟的问题
生产环境下MySQL的主从同步模式(maser-slave)很常见,但对于跨机房部署的集群,会出现同步延时的情况。举个栗子:
一条订单状态是未付款,master节点修改成已付款,可由于某些原因出现延迟数据未能及时同步到slave,这时用户立即查看订单状态(查询走slave)显示还是未付款,哪个用户看到这种情况不得慌啊。
为什么会出现主从同步延迟呢?
当主库master的TPS并发较高时,master节点并发产生的修改操作,而slave节点的sql线程是单线程处理同步数据,延时自然而言就产生了。
不过造成主从同步的原因不止这些,由于主从服务器存在跨机器并且跨机房,除了网络带宽原因之外,网络的稳定性以及机器之间的同步,都是主从同步应该考虑的主要原因。
总结
本文只是简单实现canal监听数据库的功能,旨在给大家提供一种解决问题的思路,还是反复絮叨的那句话,解决问题的技术方法很对,具体如何应用还需结合具体业务。
本文转载自网络,原文链接:https://mp.weixin.qq.com/s/hdzfTZsqWuGrIPIyh3U-AQ
 相关文章
相关文章

 精彩导读
精彩导读
 热门资讯
热门资讯