ЮФеТФПТМ
ЧАбд
CгябджаЖдзжЗћКЭзжЗћДЎЕФДІРэКмЪЧЦЕЗБ,ЕЋЪЧCгябдБОЩэЪЧУЛгазжЗћДЎРраЭЕФ,зжЗћДЎЭЈГЃЗХдк ГЃСПзжЗћДЎ жа
Лђеп зжЗћЪ§зщ жаЁЃ зжЗћДЎГЃСП ЪЪгУгкФЧаЉЖдЫќВЛзіаоИФЕФзжЗћДЎКЏЪ§.
вђДЫДЫЦЊЮФеТБуЪЧНщЩмзжЗћКЭзжЗћДЎКЏЪ§ЕФЪЙгУгызЂвтЪТЯю.
зжЗћДЎГЄЖШКЏЪ§strlen
1.strlenЕФЪЙгУ(НгЪеЕижЗ)
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "abcdefg";
char arr2[] = {'a','b','c','d','e','f','g'};
printf("%d",strlen(arr1));
printf("%d",strlen(arr2));
return 0;
}
ЩЯУцЕФНсЙћЪЧ:
7
ЫцЛњжЕ (вђЮЊ
strlenНгЪеЪздЊЫиЕижЗШЛКѓЯђКѓВщевЕН\0ЭЃжЙ,ЕЋЪЧarr2ВЂУЛга\0НсЮВ,ЫцвтЪЧЫцЛњжЕ)
2.ЪЙгУstrlenЕФаЁПг
ЯТУцвЛЖЮДњТы,ФуОѕЕУД№АИЪЧЖрЩй??
#include <stdio.h> #include <string.h> int main() { const char*str1 = "abcdef"; const char*str2 = "bbb"; if(strlen(str2)-strlen(str1)>0) { printf("str2>str1\n"); } else { printf("srt1>str2\n"); } return 0; }НсЙћЪЧЪВУДФи???
Д№АИЪЧ:
str2>str1вђЮЊ
strlenЕФЗЕЛижЕЪЧЮоЗћКХећаЭ,ЫљвдЮоЗћКХМѕШЅЮоЗћКХвЛЖЈЪЧДѓгкЕШгк0ЕФ
strlenЕФФЃФт(МЦЪ§ЗЈ ЕнЙщ жИеыЯрМѕ)
01 МЦЪ§ЗЈ
size_t my_strlen(char* str)
{
unsigned int count = 0;
while(*str)
{
count++;
str++;
}
return count;
}
02 ЕнЙщЗЈ
size_t my_strlen(char* str)
{
if (*str != 0)
{
return 1 + my_strlen(++str);
}
return 0;
}
03 жИеыЯрМѕЗЈ
size_t my_strlen(char* str)
{
char* ret = str;
while(*str) str++;
return str-ret;
}
ГЄЖШВЛЪмЯожЦЕФзжЗћДЎКЏЪ§
strcpy
ЙйЗНаДЗЈ
char* strcpy(char* strDestination, const char* strSource);МДЕквЛИіВЮЪ§ЪЧФПЕФЕиЕижЗ,ЕкЖўИіВЮЪ§дДЕижЗ,
Р§зг:
#include <stdio.h> #include <string.h> int main() { char arr1[] = "abcdef"; char arr2[] = "FF"; strcpy(arr1,arr2); printf("%s",arr1); return 0; }НсЙћ:
FFзЂвтЕу: етРяЕФИДжЦЦфЪЕВЂВЛЪЧеце§ЕФИДжЦ,зМШЗЕФЫЕЪЧИВИЧ,МДАбarr2ЕФЫљгаФкШн(АќРЈ
\0)ЖМИВИЧЕНarr1ЖдгІЮЛжУ,вВОЭЪЧЫЕЫфШЛДђгЁГіРД
arr1ЪЧFF,ЕЋЪЧЪЕжЪЩЯarr1ЕШгкFF\0defВЛаХПДЯТУцЕФЭМ
зЂвтЪТЯю:
дДзжЗћДЎБиаывд ЁЎ\0ЁЏ НсЪјЁЃ,ШчЙћдзжЗћДЎУЛга\0,ОЭЛсвЛжБПНБДдзжЗћДЎЕижЗКѓУцЕФЫљгаФкШн,жБЕНевЕНжЕЮЊ0
ЛсНЋдДзжЗћДЎжаЕФвВ ЁЎ\0ЁЏ ПНБДЕНФПБъПеМфЁЃ
**ФПБъПеМфБиаызуЙЛДѓ,вдШЗБЃФмДцЗХдДзжЗћДЎЁЃ**ШчЙћФПБъПеМфВЛЙЛДѓ,дђЛсЕМжТдДзжЗћДЎПНБДВЛНјШЅ;
ФПБъПеМфБиаыПЩБф,МДФПБъПеМфУЛга
constаоЪЮ
ФЃФтЪЕЯжstrcpy
char* my_strcpy(const char* destination,const char* source)
{
assert(destination && source);
while(*(char*)destination++ = *(char*)source++) ;
return destination;
}
strcat
ЙйЗНаДЗЈ
char* strcat( char* strDestination, const char *strSource);МДЕквЛИіВЮЪ§ЪЧФПЕФПеМф ЕкЖўИіВЮЪ§ЪЧдДТыПеМф
ЪЙгУР§зг:
#include <stdio.h> #include <string.h> int main() { char arr1[10] = "abcd"; char arr3[] = "ABCD"; my_strcpy(arr1, arr3); printf("%s", arr1); return 0; }Д№АИ:
abcdABCDЕЋЪЧШчЙћетбљФи
#include <stdio.h> #include <string.h> int main() { char arr1[] = "abcd"; char arr3[] = "ABCD"; my_strcpy(arr1, arr3); printf("%s", arr1); return 0; }Д№АИ:
БЈДэ!!! вђЮЊФПБъПеМф
arr1ДѓаЁВЛЙЛзАЯТдйзЗМг,ЫљвдЮвУДдкЪЙгУstrcatЪБКђвЛЖЈвЊзЂвтФПБъПеМфЕФДѓаЁ,ЭЌЪБдДзжЗћДЎвЛЖЈвЊ\0НсЮВЬсаб: зЗМгдРэЪЧЪзЯШевЕНdestinationЕФ\0,ШЛКѓдк\0ЩЯзЗМгsource
БШШчЯТУц
#include <stdio.h> #include <string.h> int main() { char arr1[11] = "ab\0dxxxxxx"; char arr3[] = "ABCD"; strcat(arr1,arr3); printf("%s", arr1); return 0; }
ЮвУЧПЩвдПДЕН
arr1Дгab\0dxxxxxxБфГЩСЫabABCD\0xxxвђЮЊЫћЪЧевЕНЕквЛИі\0,ШЛКѓдк\0ЩЯзЗМг.
Ьсаб:ШчЙћздМКИјздМКзЗМгЛсБРРЃ.вђЮЊ\0БЛИВИЧСЫ
змНс:
-
дДзжЗћДЎБиаывд ЁЎ\0ЁЏ НсЪјЁЃ
-
ФПБъПеМфБиаыгазуЙЛЕФДѓ,ФмШнФЩЯТдДзжЗћДЎЕФФкШнЁЃ
-
ФПБъПеМфБиаыПЩаоИФЁЃ
strcatЕФФЃФтЪЕЯж
char* ,my_strcat(char* strDestination, const char* strSource)
{
char* ret = strDestination;
/*ЯШевЕНФПБъПеМфЕФ\0*/
while(*strDestination) strDestination++;
/*ПЊЪМзЗМг*/
while(*strDestination++= *(char*)strSource++);
return ret;
}
strcmp
ШчЙћгаЯТУцЕФЬт:
#include <stdio.h>
int main()
{
char* p1 = "abcdef";
char* p2 = "aqwer";
if(p1 < p2) printf("-1\n");
if(p1 == p2) printf("0\n");
if(p1 > p2) printf("1\n");
return 0;
}
Д№АИ: 0
ФуЛсЗЂЯж,
p1гыp2ВЂУЛгаеце§ЕФдйБШНЯШЋВПзжЗћ,ЖјЪЧБШНЯСЫЕквЛИізжЗћВПЗж.вђДЫЮвУЧЯывЊеце§ЕФБШНЯзжЗћДЎОЭашвЊвЛИіКЏЪ§: ----->
strcmp
int strcmp ( const char * str1, const char * str2 );
- ШчЙћЕквЛИізжЗћДЎДѓгкЕкЖўИізжЗћДЎ,дђЗЕЛиДѓгк0Ъ§зж
- ШчЙћЕквЛИізжЗћДЎЕШгкЕкЖўИізжЗћДЎ,дђЗЕЛи0
- ШчЙћЕквЛИізжЗћДЎаЁгкЕкЖўИізжЗћДЎ,дђЗЕЛиаЁгк0Ъ§зж
Р§Шч:
#include <stdio.h> int main() { char* p1 = "abcdef"; char* p2 = "aqwer"; char* p3 = "aavd"; char* p4 = "abcdef"; printf("%d\n", strcmp(p1, p2)); printf("%d\n", strcmp(p1, p3)); printf("%d\n", strcmp(p1, p4)); return 0; }

strcmpФЃФтЪЕЯж
int my_strcmp(const char* arr1, const char* arr2)
{
while (*(char*)arr1 && (*(char*)arr1 == *(char*)arr2))
{
(char*)arr1++;
(char*)arr2++;
}
if (!*(char*)arr1) return 0;
/*ЕБЬјГібЛЗОЭБэЪОХіЕНВЛвЛбљЕФСЫ,ЫљвдЗЕЛиВюжЕ*/
return *(char*)arr1 - *(char*)arr2;
}
ГЄЖШЪмЯожЦЕФКЏЪ§
ЧАУцЕФШ§ИіВЛЪмГЄЖШЯожЦЕФКЏЪ§гаОжЯоад:
БШШчstrcpy:------->дДзжЗћДЎашвЊФЉЮВга\0,ЧвБиаыПНБДЕН\0НсЪј,ВЛЙиаФЪЧЗёФПЕФЕизАЕУЯТдДзжЗћДЎ,ГХБЌОЭБЈДэ
? strcat:------->дДзжЗћДЎашвЊФЉЮВга\0,ЧвБиаызЗМгЕН\0НсЪј,ВЛЙиаФЪЧЗёФПЕФЕизАЕУЯТдДзжЗћДЎ,ГХБЌОЭБЈДэ
? strcmp:------->дДзжЗћДЎашвЊФЉЮВга\0,ЧвБиаыБШНЯЕН\0НсЪј,ВЛЙиаФЪЧЗёФПЕФЕизАЕУЯТдДзжЗћДЎ,ГХБЌОЭБЈДэ
вђДЫ,БфгаСЫЯТУцЕФгыЧАШ§епЙІФмЯрЫЦ,ЕЋЪЧПЩвдПижЦЪ§СПЕФГЄЖШЪмЯоКЏЪ§
strncpy
гУЗЈгыstrcpyвЛбљ,ЕЋЪЧЖрСЫИіВЮЪ§ size_t count,МДашвЊПНБДЕФзжЗћЪ§СП
char * strncpy ( char * destination, const char * source, size_t count );
гУЗЈ:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "abcdefg";
char arr2[] = "XXXX";
strncpy(arr1,arr2,3);
printf("%s",arr1);
return 0;
}
Д№АИ:
XXXdefgФуЛсПДЕН,ВЂУЛгадйАб
arr2ЕФ\0ИјЗХНјarr1
**зЂвтЕу:**ЕБcountЕФЪ§СПДѓгкarr2ЕФГЄЖШЪБКђ,ЛсздЖЏгУ\0ВЙЪ§,БШШч:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "abcdefghijklmnopq";
char arr2[] = "XXXX";
strncpy(arr1,arr2,15);
printf("%s",arr1);
return 0;
}

ПЩвдЧхГўЕФПДЕНarr1РяУцЕФФкШн:здЖЏВЙГфСЫКмЖр\0
ФЃФтЪЕЯжstrncpy
char* my_strncpy(char* str1, const char* str2, size_t count)
{
char* ret = str1;
while (count&& (*str1++ = *(char*)str2++)) count--;
if (count)
/*--count ЪЧвђЮЊstr1вбОЮЊ\0,ВЛдйашвЊМЬајИГжЕ\0,ЫљвдЯШМѕвЛЯТ*/
while (--count) *str1++ = '\0';
return ret;
}
strncat
гУЗЈгы
strcatвЛбљ,ЕЋЪЧЖрСЫИіВЮЪ§size_t count,МДашвЊзЗМгЕФзжЗћЪ§СП
char * strncat ( char * destination, const char * source, size_t count );
гУЗЈЪОР§:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[50] = "abcdef\0abcdefghilj";
char arr2[] = "XXXX";
strncat(arr1, arr2, 15);
printf("%s", arr1);
return 0;
}
Д№АИ:
abcdefXXXXЖјЕБ
count>arr2ЪБ,ОЭВЛдйЙм
ФЃФтЪЕЯжstrncat
char* my_strncat(char* str1, const char* str2, size_t count)
{
char* ret = str1;
while (*str1) str1++;
while (count-- && (*str1++ = *(char*)str2++));
return ret;
}
strncmp
int strncmp ( const char * str1, const char * str2, size_t num );гУЗЈгыЧАУцвЛбљ,ЮвОЭВЛдйзИЪідѕУДгУ,жБНгПЊЪМФЃФт
strncmpЕФФЃФтЪЕЯж
int my_strncmp(const char* str1, const char* str2, size_t num)
{
while (num-- && *str1 && (*str1 == *str2))
{
str1++;
str2++;
}
return *(char*)str1 - *(char*)str2;
}
зжЗћДЎЕФВщев
strstrЙІФмЪЧВщеввЛИізжЗћДЎЪЧЗёЪЧСэвЛИізжЗћДЎЕФзгДЎ.
- ВЂЧвШчЙћевЕНОЭЗЕЛидкФПЕФЕижадДзжЗћДЎЕФЕквЛИіЕижЗ,евВЛЕНОЭЗЕЛиПежИеы(NULL)
Р§Шч :
#include <stdio.h> #include <string.h> int main () { char str[] ="This is a simple string"; char * pch; pch = strstr (str,"simple"); if (pch != NULL) strncpy (pch,"sample",6); puts (str); return 0; }НсЙћ:
This is a simple string,ПЩвдПДМћ,ЫфШЛЧАУцЕїгУСЫstrncpyЕЋЪЧЖдstrКУЯёВЂУЛгагАЯь,вђЮЊpchЪЧНЋНгЪеЕФЪЧstrжаЕФsimpleЕФЪзЕижЗ.МДS
ФЃФтЪЕЯжstrstr
char* my_strstr(const char* dest,const char* src)
{
/*ЕквЛВН,вЛвЛБШНЯ.ЕБsrcЖМБШНЯЭъСЫ(*srcЕШгк\0),дђЫЕУїЪЧзгДЎ*/
while(*dest) //ШЗБЃdestУПИізжЗћКѓУцЕФзжЗћДЎгыsrcЦЅХф
{
char* ret = dest;
//вЛвЛБШЖд,ЕБsrcЕШгк\0,ЫЕУїШЋВПБШЖдЭъГЩ.
while((*ret == *src) && (*src!='\0'))
{
ret++;
src++;
}
if(!*src) return dest;
(char*)dest++;
}
return NULL;
}
ЯёЩЯУцетбљецЕФЭъБЯСЫТ№??? ЮвУЧЫЦКѕжЛДІРэСЫ ЯёЯТУцвЛбљЕФР§зг:
ФПБъ:
"abcdefg"дДДЎ:
"cdef"
ФЧУД,ЛЙгаЪВУДВЛвЛбљЕФР§згЮвУЧУЛгаПМТЧЕНФи???ХЖ??КУЯёЪЧетИі
ФПБъ:
"abcdefg"дДДЎ:
"defghi"
ЖјЧвКУЯёЛЙгаетИі
ФПБъ:
"ABCDDDEFGH"дДДЎ:
"DDEFG"етжжЧщПіШчЙћжЛгУзюПЊЪМФЃФтЕФЧщПі,дђЛсЗЕЛиПежИеы.
ЫљвдеыЖдЕкЖўжжгыЕкШ§жжЧщПі,ФкВубЛЗЛЙгІИУгаСэЭтвЛИіЬѕМў,МД*dest ! = '\0' .
ВЂЧв,УПИізжЗћКѓУцЕФзжЗћДЎБШНЯЭъБЯ,жИеыгжЗЕЛиЕНЫљБШНЯзжЗћДЎПЊЭЗ.вђДЫ,ЬэМгвдЯТДњТы
char* my_strstr(const char* dest, const char* src)
{
char* s1;
char* s2;
char* cur = (char*)dest;
/*ЕквЛВН,вЛвЛБШНЯ.ЕБsrcЖМБШНЯЭъСЫ(*srcЕШгк\0),дђЫЕУїЪЧзгДЎ*/
while (*cur) //ШЗБЃdestУПИізжЗћКѓУцЕФзжЗћДЎгыsrcЦЅХф
{
s1 = (char*)cur;
s2 = (char*)src;
//вЛвЛБШЖд,ЕБsrcЕШгк\0,ЫЕУїШЋВПБШЖдЭъГЩ
while ((*s1 != '\0') && (*s2 != '\0')&&(*s1 == *s2))
{
s1++;
s2++;
}
if (!*s2) return cur;
cur++;
}
return NULL;
}
СэЭт,ЖдгкЧѓзгзжЗћДЎЕФЫуЗЈЛЙгаKMP,ПЩвдВЮПМвЛЮЛДѓРаЕФЮФеТKMP
strtok
зжЗћДЎЗжИюКЏЪ§,МДФПБъзжЗћДЎЭЈЙ§ЩшжУЕФЗжИюЗћНјааЗжИюГіРД
ЙйЗНаДЗЈ:
char * strtok ( char * str, const char * delimiters );ЕквЛИіВЮЪ§ЪЧФПБъ**
БЛЗжИюзжЗћДЎ,ЕкЖўИіВЮЪ§ЪЧЗжИєЗћМЏКЯ**гУЗЈ:
- ДЋШывЛЗнСйЪБПНБДЕФзжЗћДЎИј
str,вђЮЊВЛЯывЊдДзжЗћДЎБЛеце§ЕФЗжИю.- ЖдгкЭЌвЛИізжЗћДЎ,ЕквЛДЮЕїгУ,БиаыДЋШыЕижЗ,ЕкЖўДЮвдМАЖрДЮДЋШы
NULL- Ждгк
strtokЕФУюгУвЛАуЪЧЪЙгУforбЛЗ.- ЮДЗжИюЭъЪБ,ЗЕЛижЕЪЧБЛЗжИюЕФаЁЖЮзжЗћДЎЕФЪзЕижЗ,ЗжИюЭъЪБ,ЗЕЛиNULL
ЪОР§1:
#include <stdio.h>
#include <string.h>
int main()
{
char str[] = "www.123pao@qq.com/cn";
char delimiters[] = ".@/";
printf("%s\n",strtok(str,delimiters));
printf("%s\n",strtok(NULL,delimiters));
printf("%s\n",strtok(NULL,delimiters));
printf("%s\n",strtok(NULL,delimiters));
return 0;
}
НсЙћ
ЧЩУюгУЗЈЪОР§2:
#include <stdio.h>
#include <string.h>
int main()
{
char str[] = "www.123pao@qq.com/cn";
char delimiters[] = ".@/";
char* p;
for(p = strtok(str,delimiters);p != NULL;p = strtok(NULL,delimiters))
{
printf("%s\n",p);
}
return 0;
}
НсЙћ:
ДэЮѓаХЯЂБЈИц
strerror
ЙйЗНаДЗЈ: char * strerror ( int errnum ) МДЪфШывЛИіДњБэДэЮѓТыЕФећЪ§,ШЛКѓЛсЗЕЛиДэЮѓаХЯЂ
ЪОР§1:
#include <stdio.h>
#include <string.h>
int main()
{
printf("%s\n",strerror(0));
printf("%s\n",strerror(1));
printf("%s\n",strerror(2));
printf("%s\n",strerror(3));
return 0;
}
НсЙћ:
ЕЋЪЧетИіКЏЪ§ЮвУЧОГЃгУдкФФРяФи???,Д№АИЪЧХфКЯerrnoЪЙгУ
errnoЪЧвЛИіШЋОжЕФДэЮѓТыБфСП- ЕБCгябдПтКЏЪ§дкжДааЙ§ГЬжа,ЗЂЩњДэЮѓ,ОЭЛсАбЖдгІДэЮѓТы,ИГжЕЕН
errnoжа.
ЪОР§2:
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main()
{
FILE* pf = fopen("text.txt","r");//ЫцБуаДЕФвЛИіЮФМўУћ,ВЂВЛДцдк.
if(pf == NULL) printf("%s",strerror(errno));
else printf("ДђПЊГЩЙІ!!!!!!!");
return 0;
}
НсЙћ:
зжЗћЗжРрКЏЪ§(ашвЊв§Шы<ctype.h>)
iscntrl ШЮКЮПЩПизжЗћ
isspace ПеАззжЗћ:ПеИё, \f(ЛЛвГ), \n(ЛЛаа),\t(ЫЎЦНжЦБэЗћ),\r(ЛиГЕ),\v(ДИзгжЦБэЗћ)
isdigit МьбщЪЎНјжЦЪ§зж 0 ~ 9
isxdigit Мьбщ16НјжЦЪ§зж 0 ~ F
islower МьбщЪЧЗёЪЧаЁаДзжФИ a ~ z
isupper МьбщЪЧЗёЪЧДѓаДзжФИ A ~ Z
isalpha МьбщЪЧЖМЪЧзжФИ a ~ z КЭ A ~ Z
isalnum МьбщЪЧЗёЪЧЪ§зжКЭзжЗћ 0~9 a~z A~Z
бщжЄ:ЫцЛњгУМИИіКЏЪ§ЪОЗЖ
#include <stdio.h>
#include <ctype.h>
int main()
{
char num[] = "abEF 123";
printf("%d\n",islower(num[0]));
printf("%d\n",isupper(num[2]));
printf("%d\n",isdigit(num[5]));
return 0;
}
НсЙћ:
2 1 4
ЕЋЪЧВЛЭЌЕчФдПЩФмВЛЭЌНсЙћ.вђЮЊжЛвЊЗћКЯОЭЗЕЛиЕФЪЧ ЗЧСуЪ§
зжЗћзЊЛЛКЏЪ§(tolowerКЭtoupper)
#include <stdio.h>
#include <ctype.h>
#include <string.h>
int main()
{
char a[] = "abcdef";
char b[] = "ASDFG";
for (int i = 0; i < strlen(a); i++)
{
printf("%c",toupper(a[i]));
}
printf("\n");
for (int i = 0; i < strlen(b); i++)
{
printf("%c", tolower(b[i]));
}
printf("\n");
return 0;
}

ФкДцКЏЪ§
ЩЯУцЮввбОа№ЪіСЫКмЖрЕФЙигкзжЗћДЎЕФДІРэКЏЪ§
АќРЈвдЯТ:
strlenstrcpystrcatstrcmpstrncpystrncatstrncmpstrstrstrtokзжЗћЗжРрКЏЪ§ зжЗћзЊЛЛ КЏЪ§
ЕЋЪЧЮвУЧФмЙЛУїЯдЕФЗЂЯж,ЮвУЧЖМЪЧОжЯодкДІРэ зжЗћДЎ ЩЯУц,ВЂВЛФмДІРэЦфЫћЕФРраЭ.
БШШчЮвашвЊИДжЦвЛЗнЪ§зщ,ШчЙћЮвУЧгУstrcpyЪдЪд.
#include <stdio.h>
#include <string.h>
int main()
{
int num1[] = {1,3,5,7,9};
int num2[5] = {0}; //ГѕЪМЛЏЮЊ0
strcpy(num2,num1);
for(int i= 0;i<5;i++)
{
printf("%d\n", num[i]);
}
return 0;
}
НсЙћ:
1
0
0
0
0
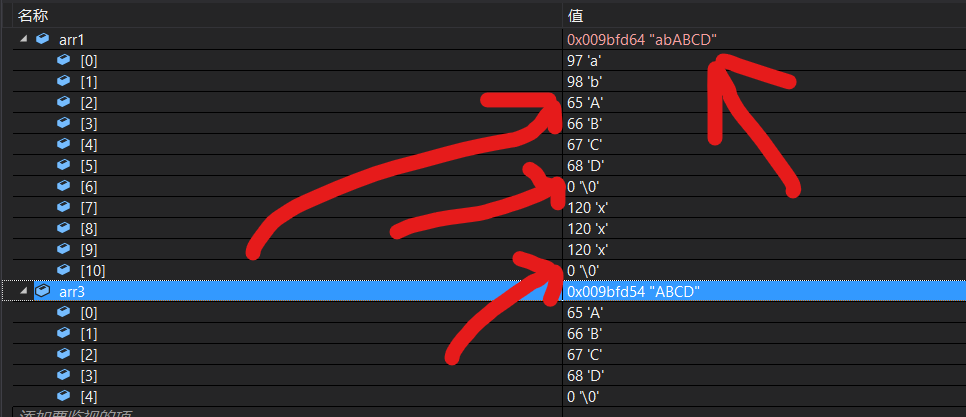
двђ: strcpy ЪЧвЛИізжНквЛИізжНкНјааИДжЦЕФ,ЖјЮвУЧЕФМЦЫуЛњДѓВПЗжЖМЪЧаЁЖЫДцДЂ.
МДЪ§зщnum1ЕФДцЗХНсЙЙШчЭМ;

ЫљвдЕБstrcpyИДжЦСЫ01 жЎКѓ,КѓУцОЭЪЧ0,БуЭЃжЙСЫИДжЦ.ЖјФПЕФЪ§зщnum2БООЭЪЧШЋВПЮЊ0,ЫљвдЕБЕквЛИізжНкБЛИДжЦвЛЗн01вдКѓ,num2[0]ЕФжЕОЭЪЧ1,ЖјКѓУцЖМУЛгаИДжЦ,ЫљвдШЋЪЧ0
вђДЫ,ЮвУЧв§ШыСЫФкДцДІРэКЏЪ§,жївЊЪЧЯТУцМИИі :
memcpymemmovememcmpmemset
memcpyЕФЪЙгУгыФЃФт
ЙйЗНЮФЕЕ:
void * memcpy ( void * destination, const void * source, size_t num );ЕквЛИіВЮЪ§: ФПЕФЕиЕижЗ
ЕкЖўИіВЮЪ§: дДзжЗћДЎЕижЗ
ЕкШ§ИіВЮЪ§: зжНкЪ§СП
memcpyЪЙгУР§зг;
#include <stdio.h>
#include <string.h>
int main()
{
int num1[5] = { 8,8,8,8,8 }; //ГѕЪМЛЏЮЊ0
int num2[5] = { 1,3,5,7,9 };
memcpy(num1, num2, 12); // 12ИізжНкОЭЪЧ3ИіећЪ§
for (int i = 0; i < 5; i++)
{
printf("%d ", num1[i]);
}
return 0;
}
НсЙћ: ****
****
ГЩЙІИДжЦ!!!
memcpyЕФФЃФтЪЕЯж
ЦфЪЕетИіФЃФтЛЙЪЧБШНЯМђЕЅЕФ(ЯрБШгк
qsortЕФФЃФт),вђЮЊЖМгУЕНСЫ ЭђФмжИеыvoid*,НгЪевЛЧа
дкЮвУДЪЕЯжетИіКЏЪ§жЎЧА,ЮвУЧашвЊЪзЯШШЗЖЈЫћЪЧдѕУДИДжЦЕФЁЧАУцвбОЫЕЙ§,ЪЧвЛИізжНквЛИізжНкИДжЦЕФ.ФЧУДЮвУЧПЯЖЈашвЊвЛИібЛЗ,ЧвбЛЗ20ДЮ,ЕЋЪЧНгЪеЕФВЮЪ§ЖМЪЧжИеы,ЖјЧв ФПЕФЕиЛЙЪЧ void*жИеы,ФЧУДдѕУДСЌНгЩЯ ЕкШ§ИіВЮЪ§гы ЕквЛИіВЮЪ§Фи?,Д№АИЪЧ зжЗћжИеы
вђЮЊвЛИізжЗћжИеыЕФЬјдОадОЭЪЧ вЛИізжНк,ИеКУЗћКЯ size_t num
void* my_memcpy(void* dest, const void* src, size_t num)
{
char* ret = dest;
while (num--)
{
*(char*)dest = *(char*)src;
++(char*)dest;
//жЎЫљвдЧАжУ++,ЪЧвђЮЊНсКЯад++Ипгк(РраЭзЊЛЏ),ЖјdestгыsrcЖМЪЧvoid*
//ВЛФмМгМѕ,ЫљвдОЭЛсБЈДэ,ЫљвдБфГЩЧАжУ++
++(char*)src;
}
return ret;
}
memmoveЕФЪЙгУгыФЃФт
ЙйЗНЮФЕЕ:
void * memcpy ( void * destination, const void * source, size_t num );гУЗЈгы
memcpyвЛФЃвЛбљ.етРяОЭВЛдйзИЪі.ФЧУДЫћЕФЙІФмЪЧЪВУДФи?? ЫћЕФЙІФмвВгы
memcpyвЛФЃвЛбљ,ФЧЮвУЧЛЙбЇЯАЪВУДФи??ФЧУД,ШчЙћЮвУЧгУздМКаДЕФКЏЪ§
my_memcpyЪЕЯжАбздМКЕФвЛВПЗжИДжЦЕНСэвЛВПЗжШЅФи???БШШчЯТУцР§зг:
int arr[] = {1,2,3,4,5,6,7,8,9,10};ШчЙћЮвЯыАб 1 2 3 4 5 ЗХЕН 4 5 6 7 8ЕФЮЛжУФи??ШчЙћЪЙгУздМКЪЕЯжЕФ
my_memcpyД№АИЪЧетбљЕФ1 2 3 1 2 3 1 2 9 10
ЮЊЪВУДФи??вђЮЊЕБПеМфжиЕўЪБКђ,здМКШЅИДжЦздМКЪБКђ,гавЛВПЗжОЭЛсБЛИВИЧ,ШчЭМ

ЖјmemmoveЕФзїгУОЭЪЧРДЪЕЯжжиЕўПеМфЕФИДжЦ
ЫуЗЈУшЪі:
ФЧУДжиЕўПеМфЮвУЧдѕУДРДЪЕЯжНјааИДжЦФи???
КмМђЕЅ,ЮвУЧЕЙзХРДЗХ.БШШчИеВХЕФ1 2 3 4 5 ЗХЕН 4 5 6 7 8,
ЮвУЧДгКѓПЊЪМ,ЯШАб5 ЗХЕН 8ЮЛжУ-------> 4ЗХЕН 7ЮЛжУ----->3ЗХЕН6ЮЛжУ------>2ЗХЕН5ЮЛжУ------->1ЗХЕН4ЮЛжУ
ЮЪЬт1 :
ЫљгаЕФЖМПЩвдетбљТ№?? ФЧЮвШчЙћЯывЊАб4 5 6 7 8 ЗХЕН1 2 3 4 5ЮЛжУФи???ШчЙћЕЙзХЗХ,ОЭЛсгжЛьТв.вђДЫЮвУЧЪЧашвЊЗжЧщПіНјааЩшМЦЕФ.
ЧщПі1:
ФПЕФЮЛжУдкдДЮЛжУжЎКѓ,БШШч1 2 3 4 5ЪЧдДЮЛжУ,1ОЭЪЧдДЪзЕижЗ. Жј4 5 6 7 8ЪЧФПЕФЕижЗ,Жј4ОЭЪЧФПЕФЪзЕижЗ.етЗћКЯФПЕФЮЛжУдкдЮЛжУжЎКѓ,ОЭВЩгУ ДгКѓЯђЧАИДжЦ
ЖјетжжЧщПіЕФФбЕуОЭЪЧдѕУДевзюКѓвЛИідЊЫиЕФзюКѓвЛИізжНкЮЛжУ
Д№АИЪЧ
dest+num-1КЭsrc + num -1,ЮЊКЮ??МћЭМ:
ЧщПі2:
Г§ШЅ
ЧщПі1ЕФЧщПі,ОЭЖМВЩгУ АЄзХЫГађИДжЦ
ФЃФт:
void* my_memmove(void* dest,const void* src,size_t num)
{
char* ret = dest;
if(dest > src)
{
while(num--)
{
//вђЮЊетРявбОМѕСЫвЛДЮ,ЫљвдВЛдйашвЊnum-1;
*((char*)dest + num) = *((char*)src + num);
}
}
else
{
while(num--)
{
*(char*)dest = *(char*)src;
++(char*)dest;
++(char*)src;
}
}
return ret;
}
гаШЫЛсЮЪ:ФЧУДЮвЦЋвЊгУmemcpyНјаажиЕўПеМфЪдЪд,ааТя??аа!!!
дкзюЕзВу,
memcpyЪЕМЪЩЯЪЧгыmemmoveвЛФЃвЛбљЕФ.ЖМПЩвдИДжЦ жиЕўаагыЗЧжиЕўадЕФПеМф,ЕЋЪЧЮЊЪВУДЮвУЧвЊХЊСНИіФи>НтЪЭ:
дкcгябдБъзМРяУц:
memcpyжЛашвЊЪЕЯжВЛжиЕўПеМфИДжЦ
memmoveжЛашвЊЪЕЯжжиЕўПеМфИДжЦЖЎСЫТ№???вВОЭЪЧЫЕ,ЫћУЧЖМЪЧГЌЖюЭъГЩСЫздМКШЮЮё,ЮвУЧШЅФЃФт,жЛЪЧЮЊСЫеЦЮеЫуЗЈгыЫМЯы
ЫљвдВХЗжПЊСЫmemcpyгыmemmoveНјааФЃФт
memcmp`ЕФЪЙгУгыФЃФт
ЙйЗНЮФЕЕ:
int memcmp ( const void * ptr1, const void * ptr2, size_t num );ЕквЛИіВЮЪ§: ФПЕФЕиЕижЗ
ЕкЖўИіВЮЪ§: дДФПБъЕижЗ
ЕкШ§ИіВЮЪ§: жБНгЪ§СП
ЪЙгУ: гыЧАУцЫљНВЕФДѓжТвЛбљ.ВЛдйвЛ вЛзИЪі,ДЫДІжЛНВФЃФт.дкФЃФтжЎЧАНЈвщдйПДПДДЫЮФЩЯУцЕФ
strcmp,гавьЧњЭЌЙЄжЎУю
memcmpФЃФт
int my_memcmp(const void * ptr1, const void * ptr2, size_t num)
{
while(num-- && (*(char*)ptr1 == *(char*)ptr2))
{
++(char*)ptr1;
++(char*)ptr2; //ЮЊЪВУДЧАжУ++,жЎЧАstrcmpНВНтЙ§
}
return *(char*)ptr1 - *(char*)ptr2;
}
memsetЕФЪЙгУМАзЂвтЪТЯю
ЙйЗНЮФЕЕ:
void * memset ( void * ptr, int value, size_t num );ЕквЛИіВЮЪ§: ФПБъЕижЗ
ЕкЖўИіВЮЪ§: ФГИіШЗЖЈЕФзжЗћ
ЕкШ§ИіВЮЪ§: зжНкЪ§СП.
ЪЙгУ:
#include <stdio.h>
#include <string.h>
int main()
{
char str[10];
memset(str,'*',sizeof(str));
for(int i = 0;i<10;i++)
{
printf("%c ",str[i]);
}
return 0;
}
НсЙћ:
ДэЮѓЪЙгУзЂвтЪТЯю:
#include <stdio.h>
#include <string.h>
int main()
{
char str[10];
int num[10];
memset(str,10,sizeof(str));
memset(num,10,sizeof(str));
printf("етЪЧзжЗћЪ§зщФкШн--------------------------------\n")
for(int i = 0;i<10;i++)
{
printf("%d ",str[i]);
}
printf("етЪЧећаЭЪ§зщФкШн--------------------------------\n")
for(int i = 0;i<10;i++)
{
printf("%d ",num[i]);
}
return 0;
}
НсЙћ:
ЛсЗЂЯжећаЭЪ§зщгыЮвУЧЯыЯѓЕФВЛвЛбљ,вђЮЊвЛИіећаЭЪ§зщЪЧ4ИізжНк.
ЖјmemsetЪЧеыЖдзжНкВйзїЕФ.ЫљвдзЂвт,вЛАуЮвУЧжЛЪЧгУгкећаЭЪ§зщГѕЪМЛЏЮЊ0,Лђеп-1,етВХЪЧзМШЗЕФ
 ЯрЙиЮФеТ
ЯрЙиЮФеТ



 ОЋВЪЕМЖС
ОЋВЪЕМЖС
 ШШУХзЪбЖ
ШШУХзЪбЖ