
дкДІРэвЛаЉИДдгТпМЪБКђЃЌpythonетжжУцЯђЙ§ГЬЕФгябдЯрБШгкSQLИќЗћКЯШЫЕФЫМЮЌЗНЪНЁЃЯраХгаВЛЩйЭЌбЇдјОИаПЎЃЌШчЙћФмгУpythonДІРэЪ§ОнПтжаЕФЪ§ОнОЭКУСЫЁЃФЧУДНёЬьЫќРДСЫЁЃ
ЪзЯШгУpythonаДДІРэИДдгТпМЕФздЖЈвхЕФКЏЪ§(вЛбєжИ)ЃЌдйНЋКЏЪ§ДњТыЧЖШыSQL(ЪЈК№ЙІ)ОЭФмКЯВЂГЩСЫвЛећеаЃКUDF
ЯТУцЮвгУвЛИіРѕзгРДЫЕУївЛаЉСНепДІРэЪ§ОнЙ§ГЬжаЕФВювьЃЌдкНщЩмРѕзгжЎЧАЃЌЯШНщЩмвЛаЉwith asЁЃгыpython ДДНЈКЏЪ§ЛђепРрвЛбљЃЌwith as гУгкДДНЈжаМфБэ
МђЕЅРДзіИіНщЩм
- select
- *
- from(select * from table where dt='2021-03-30')a
ПЩвдаДГЩ
- with a as (select * from table where dt='2021-03-30' )
- select * from a
МђЕЅЕФSQLПДВЛГіетбљЕФгХЪЦ(ЩѕжСгаЕуЖрДЫвЛОй)ЃЌЕЋЪЧЕБТпМИДдгСЫжЎКѓЮвУЧОЭФмПДГіетжжгяЗЈЕФгХЪЦЃЌЫћФмДгЕзВуГщШЁжаМфБэИёЃЌШУЮвУЧжЛзЈзЂгкЕБЧАЪЙгУЕФБэИёЃЌНјЖјПЩвдНЋИДдгЕФДІРэТпМЗжНтГЩМђЕЅЕФВНжшЁЃ
ШчЯТУцЕиБэИёМЧТМСЫгУЛЇЪЪгУappЙ§ГЬжаУПИіааЮЊШежОЕиЪБМфДСЃЌЮвУЧЯыЭГМЦвЛЯТгУЛЇНёЬьгУСЫМИДЮappЃЌвдМАУПДЮЕФЦ№ЪМЪБМфКЭНсЪјЪБМфЪЧЪВУДЪБКђЃЌетИіЮЪЬтдѕУДНтФи?

SQLЪЕЯжЗНЪН
ЪзЯШгУwith as ЙЙНЈвЛИіжаМфБэ(зЂвтПДon КЭ whereЬѕМў)
- with t1 as
- (select
- x.uid,
- case when x.rank=1 then y.timestamp_ms
- else x.timestamp_ms
- end as start_time,
- case when x.rank=1 then x.timestamp_ms
- else y.timestamp_ms end as end_time
- from
- (select
- uid,
- timestamp_ms,
- row_number()over(partition by uid order by timestamp_ms) rank
- from tmp.tmpx) x
- left outer join
- (select
- uid,
- timestamp_ms,
- row_number()over(partition by uid order by timestamp_ms) rank
- from tmp.tmpx) y
- on x.uid=y.uid and x.rank=y.rank-1
- where x.rank=1 or y.rank is null or y.timestamp_ms-x.timestamp_ms>=300)
ЪзЯШЮвУЧгУПЊДАКЏЪ§ДэЮЛЯрМѕЃЌгУwhereЬѕМўЩИбЁГіЮвУЧашвЊЕФСаЃЌЦфжа
x.rank=1 ГщШЁГіЕквЛаа
y.rank is null ГщШЁзюКѓвЛбљ
y.timestamp_ms-x.timestamp_ms>=300ГщШЁТњзуЬѕМўЕФааЃЌШчЯТЃК

ЕБШЛетИіНсЙћВЂВЛЪЧЮвУЧвЊЕФНсЙћЃЌашвЊНЋЩЯЪіБэИёжаФГвЛааЪ§ОнЕФend-timeКЭЯТвЛЬѕЪ§ОнЕФstart-timeНсКЯЦ№РДЦ№РДЃЌЙЙдьГіЪБМфЖЮ
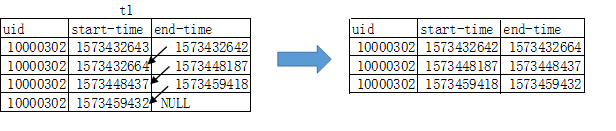
КУЕФЃЌАДееЩЯУцЮвУЧЫљЫЕЕФФЧУДЯТУцЮвУЧВЛгУЙиаФЕзВуЕФТпМЃЌНЋзЂвтСІзЈзЂгкетеХжаМфБэt1
- select
- a.uid,end_time as start_time,start_time as end_time
- from
- (select uid,start_time,row_number()over(partition by uid order by start_time) as rank from t1) a
- join
- (select uid,end_time,row_number()over(partition by uid order by end_time) as rank from t1)b
- on
- a.uid=b.uid and a.rank=b.rank+1
ЭЌбљЃЌХХађКѓДэЮЛЯрМѕЃЌШЛКѓОЭПЩвдДђЭъЪеЙЄСЫ~
UDFЪЕЯжЗНЪН
ЪзЯШЮвУЧМйЩшЩЯЪіЪ§ОнДцДЂдкcsvжаЃЌ
гУpython ДІРэБОЕиЮФМўdata.csvЃЌАДееpythonЕФДІРэЗНЪНаДДњТы(етРяОЭВЛвЛОфОфНтЪЭСЫЃЌЛсpythonЕФЭЌбЇПЩвдЬјЙ§ЃЌВЛЛсЕФЭЌбЇВЛЗСздМКЖЏЪжаДвЛЯТ)
- def life_cut(files):
- f=open(files)
- act_list=[]
- act_dict={}
- for line in f:
- line_list=line.strip().split()
- key=tuple(line_list[0:1])
- if key not in act_dict:
- act_dict.setdefault(key,[])
- act_dict[key].append(line_list[1])
- else:
- act_dict[key].append(line_list[1])
- for k,v in act_dict.items():
- k_str=k[0]+"\t"
- start_time = v[0]
- last_time=v[0]
- i=1
- while i<len(v)-1:
- if int(v[i])-int(last_time)>=300:
- print(k_str+"\t"+start_time+"\t"+v[i-1])
- start_time=v[i]
- last_time = v[i]
- i=i+1
- else:
- last_time = v[i]
- i=i+1
- print(k_str+"\t"+start_time+"\t"+v[len(v)-1])
- # print(k_str + "\t" + start_time + "\t" + v[i])
- if __name__=="__main__":
- life_cut("data.csv")
ЕУЕННсЙћШчЯТЃК
ФЧУДЯТУцЮвУЧНЋЩЯЪіКЏЪ§аДГЩudfЕФаЮЪНЃК
- #!/usr/bin/env python
- # -*- encoding:utf-8 -*-
- import sys
- act_list=[]
- act_dict={}
- for line in sys.stdin:
- line_list=line.strip().split("\t")
- key=tuple(line_list[0:1])
- if key not in act_dict:
- act_dict.setdefault(key,[])
- act_dict[key].append(line_list[1])
- else:
- act_dict[key].append(line_list[1])
- for k,v in act_dict.items():
- k_str=k[0]+"\t"
- start_time = v[0]
- last_time=v[0]
- i=1
- while i<len(v)-1:
- if int(v[i])-int(last_time)>=300:
- print(k_str+"\t"+start_time+"\t"+v[i-1])
- start_time=v[i]
- last_time = v[i]
- i=i+1
- else:
- last_time = v[i]
- i=i+1
- print(k_str+"\t"+start_time+"\t"+v[len(v)-1])
етИіБфЛЏЙ§ГЬЕФЙиМќЕуЪЧНЋ for line in f ЬцЛЛГЩ for line in sys.stdinЃЌЦфЫћЛљБОЩЯУЛЪВУДБфЛЏ
ШЛКѓЮвУЧдйРДв§гУетИіКЏЪ§
ЯШaddетИіКЏЪ§ЕФТЗОЖadd file /xxx/life_cut.py МгдиudfТЗОЖЃЌШЛКѓдйЪЙгУ
- select
- TRANSFORM (uid,timestamp_ms) USING "python life_cut.py" as (uid,start_time,end_time)
- from tmp.tmpx
змНс
ДгЩЯЪіАИР§ЮвУЧПЩвдПДГіЃЌ
UDFКЭSQLЕФЧјБ№дкгкЃЌдкДІРэИДдгТпМЪБКђЃЌUDFЯрБШSQLФмИќИпаЇЕизщжЏЦ№РДТпМВЂТфЕиЪЕЯжЙІФмЁЃUDFКЭЦеЭЈНХБОЕФЙиМќЧјБ№ЫљдкдкгкНЋ for line in f ЬцЛЛГЩ for line in sys.stdinЃЌГЃЙцКЏЪ§вЛАуЪЧНЋЮФМўвЛааааЖСШыЃЌUDFЪЧДгБъзМЪфШывЛааааМгдиЪ§ОнЁЃЯЃЭћДѓМвЦНЪБУЛЪТЕФЪБКђКУКУСЗСЗpythonЃЌЧаФЊЪщЕНгУЪБЗНКоЩйЁЃ

БОЮФзЊдиздЭјТчЃЌдЮФСДНгЃКhttps://mp.weixin.qq.com/s/fZPOiG2UR6W_Dxar0qbeNQ
 ЯрЙиЮФеТ
ЯрЙиЮФеТ

 ОЋВЪЕМЖС
ОЋВЪЕМЖС
 ШШУХзЪбЖ
ШШУХзЪбЖ