
ЧАМИЬьПДЕНвЛИі2016ФъЭІгаШЄЕФвЛИіЙЪеЯИДХЬЃЌгавЛИчУЧИјЕзВуЕФHSFЗўЮёЗЕЛижЕМгСЫвЛИізжЖЮЃЌБќГазХ“МгзжЖЮвЛЖЈЪЧАВШЋЕФ”етжжЙпадЫМЮЌОЭжБНгЩЯЯпСЫЃЌЩЯЯпКѓЗЂЯжетИіНгПкГЩЙІТЪжБНгЕј0ЃЌЯТгЮЕФЗўЮёХзГіРрЫЦЯТУцетИівьГЃЖбеЛ
- java.io.InvalidClassException:com.taobao.query.TestSerializable;
- local class incompatible: stream classdesc serialVersionUID = -7165097063094245447,local class serialVersionUID = 6678378625230229450
ПДЕНетИіЖбеЛПЩФмгаРЯЫОЛњвбОЗДгІЙ§РДСЫЃЌЯТУцЮвУЧОЭПДЯТетжжвьГЃЕНЕзЪЧШчКЮЗЂЩњЕФ
JavaађСаЛЏгыЗДађСаЛЏ
- ађСаЛЏЃКНЋЖдЯѓаДШыЕНIOСїжа
- ЗДађСаЛЏЃКДгIOСїжаЛжИДЖдЯѓ
ађСаЛЏЛњжЦдЪаэНЋЪЕЯжађСаЛЏЕФJavaЖдЯѓзЊЛЛЮЊзжНкађСаЃЌетаЉзжНкађСаПЩвдБЃДцдкДХХЬЩЯЃЌЛђЭЈЙ§ЭјТчДЋЪфЃЌвдДяЕНвдКѓЛжИДГЩдРДЕФЖдЯѓЁЃађСаЛЏЛњжЦЪЙЕУЖдЯѓПЩвдЭбРыГЬађЕФдЫааЖјЖРСЂДцдкЁЃ
вЊЯыгаађСаЛЏЕФФмСІЃЌЕУЪЕЯжSerializableНгПкЃЌОЭЯёЯТУцЕФетИіР§згвЛбљЃК
- public class SerializableTest implements Serializable {
- private static final long serialVersionUID = -3751255153289772365L;
- }
етРяУцвЛИіЙиМќЕФЕуЪЧserialVersionUIDЃЌJVMЛсдкдЫааЪБХаЖЯРрЕФserialVersionUIDРДбщжЄАцБОвЛжТадЃЌШчЙћДЋРДЕФзжНкСїжаЕФserialVersionUIDгыБОЕиЯргІРрЕФserialVersionUIDЯрЭЌдђШЯЮЊЪЧвЛжТЕФЃЌПЩвдНјааЗДађСаЛЏЃЌЗёдђОЭЛсГіЯжађСаЛЏАцБОВЛвЛжТЕФвьГЃЁЃ
дкЩЯУцЕФР§згжаЃЌЮвУЧЭЈЙ§IDEAЕФВхМўвбОздЖЏЮЊSerializableTestЩњГЩСЫвЛИіserialVersionUIDЃЌШчЙћЮвУЧВЛжИЖЈserialVersionUIDЃЌБрвыЦїдкБрвыЕФЪБКђвВЛсИљОнРрУћЁЂНгПкУћЁЂГЩдБЗНЗЈМАЪєадЕШРДЩњГЩвЛИі64ЮЛЕФЙўЯЃзжЖЮ ЁЃ
DubboгыађСаЛЏ
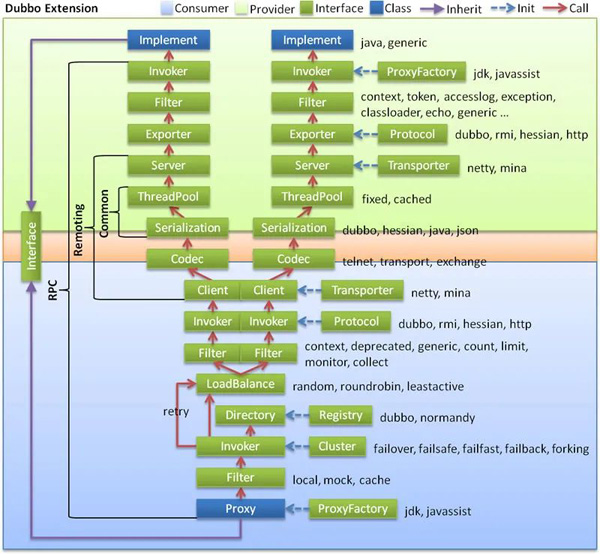
/dev-guide/images/dubbo-extension.jpg
ЭМЦЌРДдДЃКhttps://dubbo.apache.org/zh/docs/v2.7/dev/design/
ДгDubboЕФЕїгУСДПЩвдЗЂЯжЪЧгавЛИіађСаЛЏНкЕуЕФЃЌЦфжЇГжЕФађСаЛЏавщвЛЙВгаЫФжжЃК
1. dubboађСаЛЏЃКАЂРяЩаЮДПЊЗЂГЩЪьЕФИпаЇjavaађСаЛЏЪЕЯжЃЌАЂРяВЛНЈвщдкЩњВњЛЗОГЪЙгУЫќ
2. hessian2ађСаЛЏЃКhessianЪЧвЛжжПчгябдЕФИпаЇЖўНјжЦађСаЛЏЗНЪНЁЃЕЋетРяЪЕМЪВЛЪЧдЩњЕФhessian2ађСаЛЏЃЌЖјЪЧАЂРяаоИФЙ§ЕФhessian liteЃЌЫќЪЧdubbo RPCФЌШЯЦєгУЕФађСаЛЏЗНЪН
3. jsonађСаЛЏЃКФПЧАгаСНжжЪЕЯжЃЌвЛжжЪЧВЩгУЕФАЂРяЕФfastjsonПтЃЌСэвЛжжЪЧВЩгУdubboжаздМКЪЕЯжЕФМђЕЅjsonПтЃЌЕЋЦфЪЕЯжЖМВЛЪЧЬиБ№ГЩЪьЃЌЖјЧвjsonетжжЮФБОађСаЛЏадФмвЛАуВЛШчЩЯУцСНжжЖўНјжЦађСаЛЏЁЃ
4. javaађСаЛЏЃКжївЊЪЧВЩгУJDKздДјЕФJavaађСаЛЏЪЕЯжЃЌадФмКмВЛРэЯыЁЃ
ДгФЧИіЬћзгПДЕБЪБHSFЗўЮёЬсЙЉМЏШКЩшжУЕФађСаЛЏЗНЪНЪЧjavaађСаЛЏЃЌЖјВЛЪЧЯёЯждквЛбљФЌШЯhessian2ЃЌШчЙћдкRPCжаЪЙгУСЫJavaађСаЛЏЃЌФЧЯТУцЕФетШ§ИіПгвЛЖЈзЂвтВЛвЊВШ
РрЪЕЯжСЫSerializableНгПкЃЌЕЋЪЧШДУЛгажИЖЈserialVersionUID
ЮвУЧжЎЧАдкЮФжаЬсЙ§ЃЌШчЙћЪЕЯжСЫSerializableЕФРрУЛгажИЖЈserialVersionUIDЃЌБрвыЦїБрвыЕФЪБКђЛсИљОнРрУћЁЂНгПкУћЁЂГЩдБЗНЗЈМАЪєадЕШРДЩњГЩвЛИі64ЮЛЕФЙўЯЃзжЖЮЃЌетОЭОіЖЈСЫетИіРрдкађСаЛЏЩЯвЛЖЈВЛЪЧЯђЧАМцШнЕФЃЌЧАЮФжаЕФФЧИіЙЪеЯОЭЪЧВШСЫетИіПгЁЃЮвУЧдкБОЕиФЃФтвЛЯТетИіcase:
МйШчЮвУЧЯШгаStudentетбљЕФвЛИіРр
- public class Student implements Serializable {
- private static int startId = 1000;
- private int id;
- public Student() {
- id = startId ++;
- }
- }
ЮвУЧНЋЦфађСаЛЏЕНДХХЬЃК
- private static void serialize() {
- try {
- Student student = new Student();
- FileOutputStream fileOut =
- new FileOutputStream("/tmp/student.ser");
- ObjectOutputStream out = new ObjectOutputStream(fileOut);
- out.writeObject(student);
- out.close();
- fileOut.close();
- System.out.printf("Serialized data is saved in /tmp/student.ser");
- } catch (
- IOException i) {
- i.printStackTrace();
- }
- }
ШЛКѓИјStudentРрМгвЛИізжЖЮ
- public class Student implements Serializable {
- private static int startId = 1000;
- private int id;
- // зЂвтетРяЮвУЧвбОМгСЫвЛИіЪєад
- private String name;
- public Student() {
- id = startId ++;
- }
- }
ЮвУЧдйШЅНтТыЃЌЗЂЯжГЬађЛсХзГівьГЃЃК
- java.io.InvalidClassException: com.idealism.base.Student; local class incompatible: stream classdesc serialVersionUID = -1534228028811562580, local class serialVersionUID = 630353564791955009
- at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699)
- at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:2001)
- at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1848)
- at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2158)
- at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1665)
- at java.io.ObjectInputStream.readObject(ObjectInputStream.java:501)
- at java.io.ObjectInputStream.readObject(ObjectInputStream.java:459)
- at com.idealism.base.SerializableTest.deserialize(SerializableTest.java:34)
- at com.idealism.base.SerializableTest.main(SerializableTest.java:9)
ЦфЪЕЕНетРяЮвУЧОЭЭъећЕФФЃФтСЫЧАЮФжаЕФФЧИіЙЪеЯЃЌЦфИљвђЪЧRPCЕФВЮЪ§ЪЕЯжСЫSerializableНгПкЃЌЕЋЪЧУЛгажИЖЈserialVersionUIDЃЌБрвыЦїЛсИљОнРрУћЁЂНгПкУћЁЂГЩдБЗНЗЈМАЪєадЕШРДЩњГЩвЛИі64ЮЛЕФЙўЯЃзжЖЮЃЌЕБЗўЮёЖЫРрЩ§МЖжЎКѓЕМжТСЫЗўЮёЖЫЗЂЫЭИјПЭЛЇЖЫЕФзжНкСїжаЕФserialVersionUIDЗЂЩњСЫИФБфЃЌвђДЫЕБПЭЛЇЖЫЗДађСаЛЏШЅМьВщserialVersionUIDзжЖЮЕФЪБКђЗЂЯжЗЂЩњСЫБфЛЏБЛХаЖЈСЫвьГЃЁЃ
ИИРрЪЕЯжСЫSerializableНгПкЃЌВЂЧвжИЖЈСЫserialVersionUIDЕЋЪЧзгРрУЛгажИЖЈserialVersionUID
ЮвУЧЖдЧАУцЕФР§згжаЕФStudentРрЩдЮЂИФвЛЯТ
- public class Student extends Base{
- private static int startId = 1000;
- private int id;
- public Student() {
- id = startId ++;
- }
- }
ЦфжаИИРрГЄетбљЃК
- public class Base implements Serializable {
- private static final long serialVersionUID = 218886242758597651L;
- private Date gmtCreate;
- }
ШчЙћЮвУЧАДеежЎЧАЕФЬжТлдкБОЕиНјаавЛДЮађСаЛЏКЭЗДађСаЛЏЃЌГЬађвРШЛХзвьГЃЃК
- java.io.InvalidClassException: com.idealism.base.Student; local class incompatible: stream classdesc serialVersionUID = 1049562984784675762, local class serialVersionUID = 7566357243685852874
- at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699)
- at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:2001)
- at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1848)
- at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2158)
- at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1665)
- at java.io.ObjectInputStream.readObject(ObjectInputStream.java:501)
- at java.io.ObjectInputStream.readObject(ObjectInputStream.java:459)
- at com.idealism.base.SerializableTest.deserialize(SerializableTest.java:34)
- at com.idealism.base.SerializableTest.main(SerializableTest.java:9)
ЮвУЧдкЩшМЦРрЕФЪБКђЙЋЙВЪєадвЊЗХЕНЛљРрЃЌетЬѕОбщжИЕМЗХЕНетИіcaseжаШдШЛВЛЬЋе§ШЗЃЌЖјЧветИіcaseБШЩЯвЛИіЛЙвЊвўБЮЃЌЮЪЬтГіжївЊЪЧЭЈЙ§IDEAВхМўЩњГЩЕФserialVersionUIDЕФаоЪЮЗћЪЧpivateЕМжТетИізжЖЮдкзгРржаВЛПЩМћЃЌзгРржаЕФserialVersionUIDШдШЛЪЧБрвыЦїздЖЏЩњГЩЕФЁЃЕБШЛПЩвдАбИИРржаserialVersionUIDЕФИФЮЊЗЧprivateРДНтетИіЮЪЬтЃЌВЛЙ§ЮвШдШЛНЈвщУПИігаађСаЛЏашЧѓЕФРрЖМЯдЪНжИЖЈserialVersionUIDЕФжЕЁЃ
ШчЙћађСаЛЏгіЕНРржЎМфЕФзщКЯЛђепМЬГаЙиЯЕЃЌдђJavaАДееЯТУцЕФЙцдђДІРэЃК
- ЕБвЛИіЖдЯѓЕФЪЕР§БфСПв§гУЦфЫћЖдЯѓЃЌађСаЛЏИУЖдЯѓЪБвВАбв§гУЖдЯѓНјааађСаЛЏЃЌЖјВЛЙмЦфЪЧЗёЪЕЯжСЫSerializableНгПк
- ШчЙћзгРрЪЕЯжСЫSerializableЃЌдђађСаЛЏЪБжЛађСаЛЏзгРрЃЌВЛЛсађСаЛЏИИРржаЕФЪєад
- ШчЙћИИРрЪЕЯжСЫSerializableЃЌдђађСаЛЏЪБзгРрКЭИИРрЖМЛсБЛађСаЛЏЃЌвьГЃГЁОАШчБОР§ЫљжИ
ЛЙгавЛЕувЊзЂвтЃКШчЙћРрЕФЪЕР§жагаОВЬЌБфСПЃЌИФЪєадВЛЛсБЛађСаЛЏКЭЗДађСаЛЏ
РржагаУЖОйжЕ
ЁЖАЂРяАЭАЭПЊЗЂЙцдМЁЗжагаетУДвЛЬѕЃК
ЁОЧПжЦЁПЖўЗНПтР§ПЩвдЖЈвхУЖОйРраЭЃЌВЮЪ§ПЩвдЪЙгУУЖОйРраЭЃЌЕЋЪЧНгПкЗЕЛижЕВЛдЪаэЪЙгУУЖОйРраЭЛђепАќКЌУЖОйРраЭЕФPOJOЖдЯѓЁЃ
ЫЕУїЃКгЩгкЩ§МЖдвђЃЌЕМжТЫЋЗНЕФУЖОйРрВЛОЁЯрЭЌЃЌдкНгПкНтЮіЃЌРрЗДађСаЛЏЪБГіЯжвьГЃ
етРяЛсГіЯжетбљвЛИіЯожЦЕФдвђЪЧJavaЖдУЖОйЕФађСаЛЏКЭЗДађСаЛЏВЩгУЭъШЋВЛЭЌЕФВпТдЁЃађСаЛЏЕФНсЙћжаНіАќКЌУЖОйЕФУћзжЃЌЖјВЛАќКЌУЖОйЕФОпЬхЖЈвхЃЌЗДађСаЛЏЕФЪБКђПЭЛЇЖЫДгађСаЛЏНсЙћжаЖСШЁУЖОйЕФnameЃЌШЛКѓЕїгУjava.lang.Enum#valueOfИљОнБОЕиЕФУЖОйЖЈвхЛёШЁОпЬхЕФУЖОйжЕЁЃ
ЮвУЧШдШЛгУжЎЧАЕФДњТыОйР§ЃК
- public class Student implements Serializable {
- private static final long serialVersionUID = 2528736437985230667L;
- private static int startId = 1000;
- private int id;
- private String name;
- // аТдізжЖЮЃЌаЃЗўГпТыЃЌЦфРраЭЪЧвЛИіУЖОй
- private SchoolUniformSizeEnum schoolUniformSize;
- public Student() {
- id = startId ++;
- }
- }
МйШчбЇЩњетИіРржааТдіСЫвЛИіаЃЗўГпТыЕФУЖОйжЕ
- public enum SchoolUniformSizeEnum {
- SMALL,
- MEDIUM,
- LARGE
- }
МйШчЗўЮёЖЫДЫЪБЖдетИіУЖОйНјааСЫЩ§МЖЃЌЕЋЪЧПЭЛЇЖЫЕФЖўЗНАќжаШдШЛжЛгаШ§ИіжЕЃК
- public enum SchoolUniformSizeEnum {
- SMALL,
- MEDIUM,
- LARGE,
- OVERSIZED
- }
ШчЙћЗўЮёЖЫгаТпМИјПЭЛЇЖЫЗЕЛиСЫетИіаТдіЕФУЖОйжЕЃК
- private static void serialize() {
- try {
- Student student = new Student();
- // ЗўЮёЖЫЩ§МЖСЫУЖОй
- student.setSchoolUniformSize(SchoolUniformSizeEnum.OVERSIZED);
- FileOutputStream fileOut =
- new FileOutputStream("/tmp/student.ser");
- ObjectOutputStream out = new ObjectOutputStream(fileOut);
- out.writeObject(student);
- out.close();
- fileOut.close();
- System.out.printf("Serialized data is saved in /tmp/student.ser");
- } catch (
- IOException i) {
- i.printStackTrace();
- }
- }
вђЮЊПЭЛЇЖЫЕФЖўЗНАќЛЙУЛгаЩ§МЖЃЌЫљвдЕБПЭЛЇЖЫЖСЕНетИіаТЕФзжНкСїВЂађСаЛЏЕФЪБКђЛсвђЮЊевВЛЕНЖдгІЕФУЖОйжЕЖјХзвьГЃЁЃ
- java.io.InvalidObjectException: enum constant OVERSIZED does not exist in class com.idealism.base.SchoolUniformSizeEnum
- at java.io.ObjectInputStream.readEnum(ObjectInputStream.java:2130)
- at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1659)
- at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2403)
- at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2327)
- at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2185)
- at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1665)
- at java.io.ObjectInputStream.readObject(ObjectInputStream.java:501)
- at java.io.ObjectInputStream.readObject(ObjectInputStream.java:459)
- at com.idealism.base.SerializableTest.deserialize(SerializableTest.java:36)
- at com.idealism.base.SerializableTest.main(SerializableTest.java:9)
2016ФъЕФЙЪеЯЛЙжЕЕУЮвУЧШЅИДХЬТ№
ПДЕНетРяПЩФмгааЁЛяАщОѕЕУЃЌЮветБВзгЖМВЛПЩФмШЅаоИФDubboЕФађСаЛЏЗНЪНЃЌОЭШУЫћhessian2ЕНЕзАЩЃЌЮвВЛЕУВЛГаШЯШЗЪЕЪЧетбљЕФЁЃШчЙћАбађСаЛЏЙтЯожЦдкRPCетвЛИіГЁОАЃЌЮДУтгааЉЯСАЏЁЃвдАЂРяЮЊР§ЃЌЦфЗжВМЪНЛКДцжаМфМўTairЕФаДНгПкПЩНгЪмЕФШыВЮОЭЪЧвЛИіSerializableЃЌКУдкЮвУЧЦНГЃЭљЛКДцжаШћЖЋЮїЖМЪЧвдStringЮЊkeyЕФЃЌЕЋЭђвЛгаЧАШЫецЕФгУСЫвЛИіЪЕЯжСЫSerializableЕФРрЃЌВЂЧвЧЁКУУЛгажИЖЈserialVersionUIDЃЌФЧаТРДЕФФуВЛОЭе§КУВШПгСЫУДЁЃЫљвддкгіЕНађСаЛЏЕФЕиЗНашвЊзаЯИВщПДгаУЛгаВШЮФеТжаСаГіРДЕФШ§ИіПгЁЃ
БОЮФзЊдиздЭјТчЃЌдЮФСДНгЃКhttps://mp.weixin.qq.com/s/VxO0a2IEp3BwR4vC_aANIg
АцШЈЩљУїЃКБОЮФзЊдиздЭјТчЃЌзёб CC 4.0 BY-SA АцШЈавщЃЌзЊдиЧыИНЩЯдЮФГіДІСДНгКЭБОЩљУїЁЃБОеОзЊдиГігкДЋВЅИќЖргХауММЪѕжЊЪЖжЎФПЕФЃЌШчгаЧжШЈЧыСЊЯЕQQ/ЮЂаХЃК153890879ЩОГ§
 ЯрЙиЮФеТ
ЯрЙиЮФеТ-

ЬЋАєСЫЃЁPythonКЭExcelЙ§СЫетУДОУжегк
-
JavaБрГЬФкЙІ-Ъ§ОнНсЙЙгыЫуЗЈЁИЯпЫїЛЏ
-
дкJavaжаЪЙгУвьВНБрГЬ
-
KafkaадФмЦЊЃКЮЊКЮKafkaетУД"

 ОЋВЪЕМЖС
ОЋВЪЕМЖС
 ШШУХзЪбЖ
ШШУХзЪбЖ