今天一大早就被网友们安利了一个热门 AI 项目。
听说,它可以带你周游世界,还能让 AngelaBaby 多拍几部电视剧。
这是啥情况??
仔细一了解,原来是一款 AI 视频抠图神器,一大早就冲上了 GitHub 热榜。
官方介绍说,这个 AI 神器可以让视频处理变得非常简单且专业,不用「绿幕」,也能达到逼真、毫无违和感的合成效果。
果然,打工人的 “周游世界”只有 AI 能实现了 [泪目]。
其实,视频抠图 AI 已经出现过不少,但这一款确实让人觉得很惊艳。先来看下它演示 Demo。
你能看出公路背景和大海背景的视频,哪一个是 AI 合成的吗?

连撩起的头发都看不出一点破绽。
而且就算疯狂跳舞也没有影响合成效果。

再来看下它背后的抠图细节,不仅精确到了头发,甚至还包括浮起的碎发 ......

动态效果也是如此,疯狂甩头也能实时捕捉细节。

这项超强 AI 抠图神器来自香港城市大学和商汤科技联合研究团队,论文一作还是一位在读博士生张汉科。
接下来,我们来看下它背后的技术原理。
目标分解网络 MODNet
关键在于,这个 AI 采用了一种轻量级的目标分解网络 MODNet( Matting Objective Decomposition Network),它可以从不同背景的单个输入图像中平滑地处理动态人像。
简单的说,其功能就是视频人像抠图。
我们知道,一些影视作品尤其是古装剧,必须要对人物的背景进行后期处理。为了达到逼真的合成效果,拍摄时一般都会采用「绿幕」做背景。因为绿色屏幕可以使高质量的 Alpha 蒙版实时提取图像或视频中的人物。
另外,如果没有绿屏的话,通常采用的技术手段是光照处理法,即使预定义的 Trimap 作为自然光照算法输入。这种方法会粗略地生成三位图:确定的(不透明)前景,确定的(透明)背景以及介于两者之间的未知(不透明)区域。
如果使用人工注释三位图不仅昂贵,而且深度相机可能会导致精度下降。因此,针对以上不足,研究人员提出了目标分解网络 MODNet。
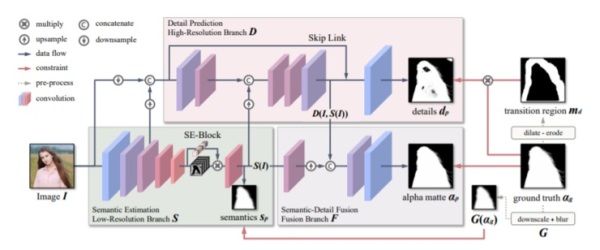
如图所示,MODNet 由三个相互依赖的分支 S、D 和 F 构成。它们分别通过一个低分辨率分支来预测人类语义(SP)、一个高分辨率分支来聚焦纵向的边界细节(DP),最后一个融合分支来预测 Alpha Matte (αp)。
具体如下:
-
语义估计(Semantic Estimation):采用 MobileNetV2[35]架构,通过编码器(即 MODNet 的低分辨率分支)来提取高层语义。
-
细节预测(Detail Prediction):处理前景肖像周围的过渡区域,以 I,S(I)和 S 的低层特征作为输入。同时对它的卷积层数、信道数、输入分辨率三个方面进行了优化。
-
语义细节融合(Semantic-Detail Fusion):一个融合了语义和细节的 CNN 模块,它向上采样 S(I)以使其形状与 D(I,S(I))相之相匹配,再将 S(I)和 D(I,S(I))连接起来预测最终αp。
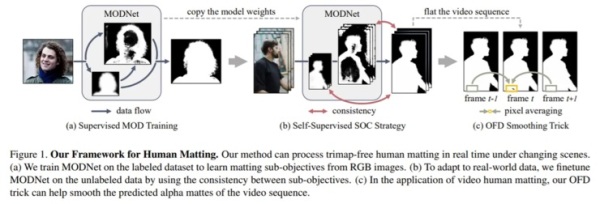
另外,基于以上底层框架,该研究还提出了一种自监督策略 SOC(Sub-Objectives Consistency)和帧延迟处理方法 OFD(One-Frame Delay )。
其中,SOC 策略可以保证 MODNet 架构在处理未标注数据时,让输出的子目标之间具有一致性;OFD 方法在执行人像抠像视频任务时,可以在平滑视频序列中预测 Alpha 遮罩。如下图:
实验评估
在开展实验评估之前,研究人员创建了一个摄影人像基准数据集 PPM-100(Photographic Portrait Matting)。
它包含了 100 幅不同背景的已精细注释的肖像图像。为了保证样本的多样性,PPM-100 还被定义了几个分类规则来平衡样本类型,比如是否包括整个人体;图像背景是否模糊;是否持有其他物体。如图:

PPM-100 中的样图具有丰富的背景和人物姿势。因此可以被看做一个较为全面的基准。
那么我们来看下实验结果:
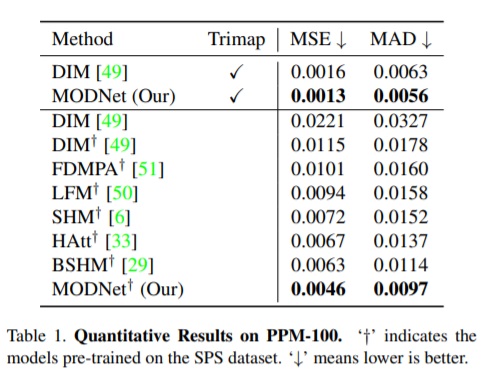
图中显示,MODNet 在 MSE(均方误差)和 MAD(平均值)上都优于其他无 Trimap 的方法。虽然它的性能不如采用 Trimap 的 DIM,但如果将 MODNet 修改为基于 Trimap 的方法—即以 Trimap 作为输入,它的性能会优于基于 Trimap 的 DIM,这也再次表明显示 MODNet 的结构体系具有优越性。
此外,研究人员还进一步证明了 MODNet 在模型大小和执行效率方面的优势。
其中,模型大小通过参数总数来衡量,执行效率通过 NVIDIA GTX1080 Ti GPU 上超过 PPM-100 的平均参考时间来反映(输入图像被裁剪为 512×512)。结果如图:
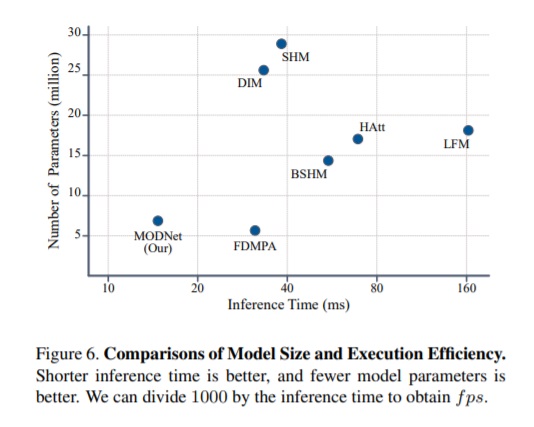
上图显示,MODNet 的推理时间为 15.8ms(63fps),是 FDMPA(31fps)的两倍。虽然 MODNet 的参数量比 FDMPA 稍多,但性能明显更好。
需要注意的是,较少的参数并不意味着更快的推理速度,因为模型可能有较大的特征映射或耗时机制,比如,注意力机制(Attention Mechanisms)。
总之,MODNet 提出了一个简单、快速且有效实时人像抠图处理方法。该方法仅以 RGB 图像为输入,实现了场景变化下 Alpha 蒙版预测。此外,由于所提出的 SOC 和 OFD,MODNet 在实际应用中受到的域转移问题影响也较小。
本文转载自网络,原文链接:https://www.ithome.com/0/522/757.htm
版权声明:本文转载自网络,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。本站转载出于传播更多优秀技术知识之目的,如有侵权请联系QQ/微信:153890879删除
 相关文章
相关文章-

AI 视频抠图有多强:无需「绿幕」,也
-
快手联手英特尔提升KGNN 平台大规模实
-
无人驾驶到底离我们还有多远?
-
这五个数据科学家和机器学习工程师油管

 精彩导读
精彩导读
 热门资讯
热门资讯