有时候,我们要从一段很长的 URL 里面提取出域名。例如从
https://www.kingname.info/2020/10/02/copy-from-ssh/,我需要获取的是kingname.info。

可能有人会这样写代码:
- url = 'https://www.kingname.info/2020/10/02/copy-from-ssh/'
- domain = '.'.join(url.split('/')[2].split('.')[1:])
运行效果如下图所示:

但如果我给出的 URL 没有带 https://,这段代码的结果就有问题。
而且,有些域名可能有三级、四级域名,例如:blog.exercise.kingname.com.cn。显然,使用点分割以后,也不知道怎么拿到真正的域名kingname.com.cn。
还有一些人的需求可能只需要域名中的名字,例如kingname.info只要kingname,google.com.hk只要google。
对于这些需求,如果手动写规则来提取的话,会非常麻烦。
不过好在 Python 有一个第三方库已经解决了这个问题,这就是tld。
我们先来安装它:
- python3 -m pip install tld
安装完成以后,我们来看看它的使用方法:
- >>> url = 'https://www.kingname.info/2020/10/02/copy-from-ssh/'
- >>> from tld import get_tld
- >>> result = get_tld(url, as_object=True)
- >>> domain = result.domain
- >>> print(domain)
- kingname
- >>> domain_with_suffix = result.fld
- >>> print(domain_with_suffix)
- kingname.info
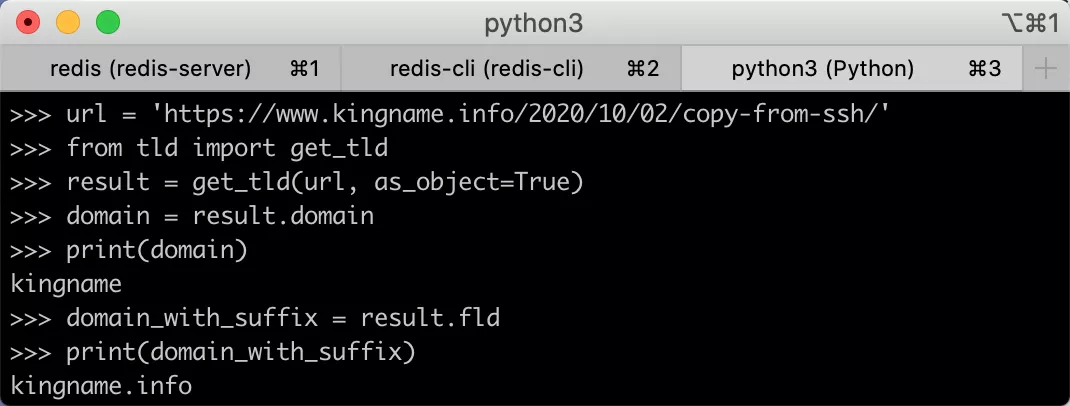
首先使用get_tld生成一个对象,然后通过对象的.domain属性获得纯域名,使用.fld属性,获得带有后缀的域名。
运行效果如下图所示:
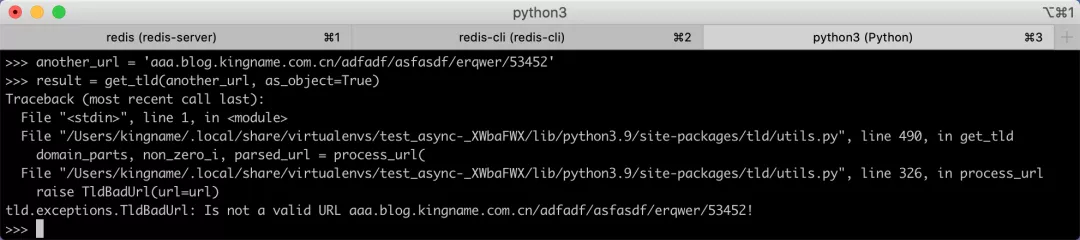
对于不含https的网址,直接使用会报错,如下图所示:
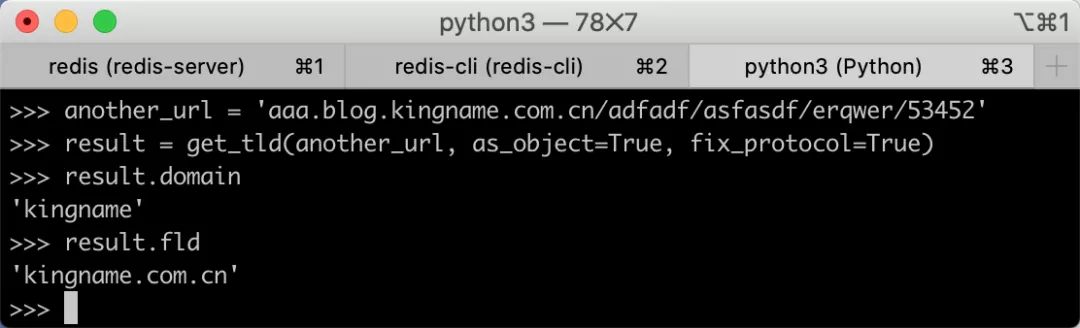
但只要加上一个参数fix_protocol=True就可以解决问题:
【责任编辑:赵宁宁 TEL:(010)68476606】
本文转载自网络,原文链接:http://mp.weixin.qq.com/s?__biz=MzI2MzEwNTY3OQ==&mid=2648979552&idx=1&sn=50eedb54e3d59d584481d82180e482dd&chksm=f2506580c527ec960e50c1b483c368cfb4d25ff40ccf0bdd3a20ae5d1a54b0f531dbf955ef1e&mpshare=1&s
本文转载自网络,原文链接:http://mp.weixin.qq.com/s?__biz=MzI2MzEwNTY3OQ==&mid=2648979552&idx=1&sn=50eedb54e3d59d584481d82180e482dd&chksm=f2506580c527ec960e50c1b483c368cfb4d25ff40ccf0bdd3a20ae5d1a54b0f531dbf955ef1e&mpshare=1&s
版权声明:本文转载自网络,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。本站转载出于传播更多优秀技术知识之目的,如有侵权请联系QQ/微信:153890879删除
 相关文章
相关文章-

如何从URL中快速提取域名?
-
Gartner:2021年及以后IT组织和用户十
-
康普观点:5G时代下运营商的网络效率变
-
开发者相约羊城打卡鲲鹏沙龙,看新计算

 精彩导读
精彩导读
 热门资讯
热门资讯